🌐 Traduzione italiana | Articolo originale: TurboQuant: Local Agent Swarms with 4M-Token Context on $5K Desktop
Questa è una traduzione automatica realizzata con AI. I contenuti e i diritti appartengono all’autore originale.
In breve, un sistema multi-agente che prima richiedeva tre abbonamenti API separati da 200 dollari al mese ciascuno può ora girare su una singola workstation con un paio di RTX 4090, completamente offline e senza costi per token.
Permettetemi di spiegare meglio.
Con una precisione a 32 bit, la KV cache per un modello da 70 miliardi di parametri che elabora 100.000 token può consumare oltre 40 GB di memoria.
Su una GPU in cloud non è un problema perché si sta noleggiando l’hardware, ma sulla propria macchina locale questo corrisponde all’intera memoria di sistema; su un dispositivo edge, è pura fantasia.
TurboQuant di Google è un algoritmo di quantizzazione che comprime la KV cache fino a 3 bit per valore, partendo dallo standard industriale di 32 bit.
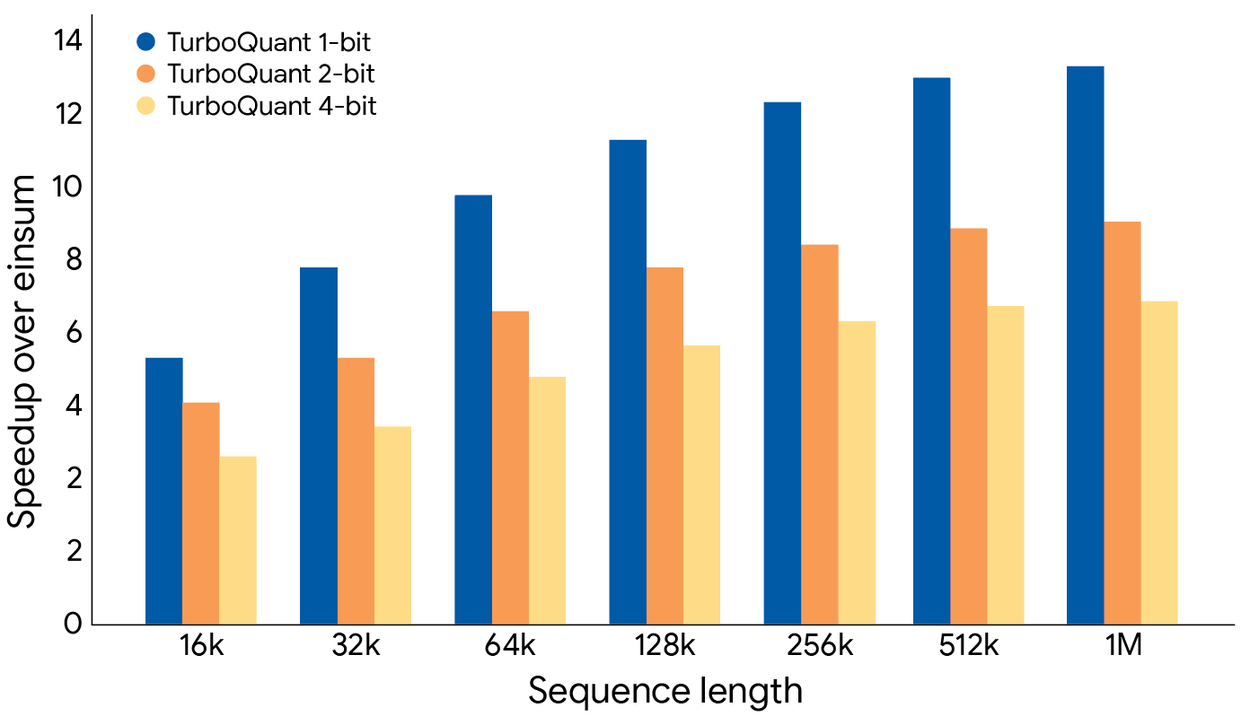
Si tratta di una riduzione della memoria di 6 volte e di un calcolo dell’attention fino a 8 volte più veloce, con zero perdite di accuratezza in cinque benchmark standard per contesti lunghi.
Ad esempio, può girare in llama.cpp su M5 Max con kernel Metal raggiungendo i benchmark di compressione (4.9x a 3-bit), oppure su HP ZGX che ora può ospitare 4.083.072 token di KV-cache su GB10.
Nota: Quattro milioni di token di contesto persistente…
Significa un’intera base di codice o settimane di cronologia di conversazione.
Significa un sistema multi-agente dove ogni agente può vedere tutto, sempre, senza riassunti, senza eliminazioni di dati (eviction) e senza le euristiche approssimative che abbiamo scritto finora per gestire le finestre di contesto.
I precedenti metodi di compressione comportavano sempre un compromesso: si poteva rimpicciolire la cache, ma si perdeva qualità.
Gli ingegneri accettavano questo patto faustiano perché non c’era alternativa, ma TurboQuant elimina completamente questo scambio.
Come funziona TurboQuant
TurboQuant è elegante nella sua costruzione. È una pipeline a due fasi basata su due sotto-algoritmi:
Fase 1: PolarQuant
Invece di comprimere i vettori nelle coordinate cartesiane standard, PolarQuant li converte in un sistema di coordinate polari.
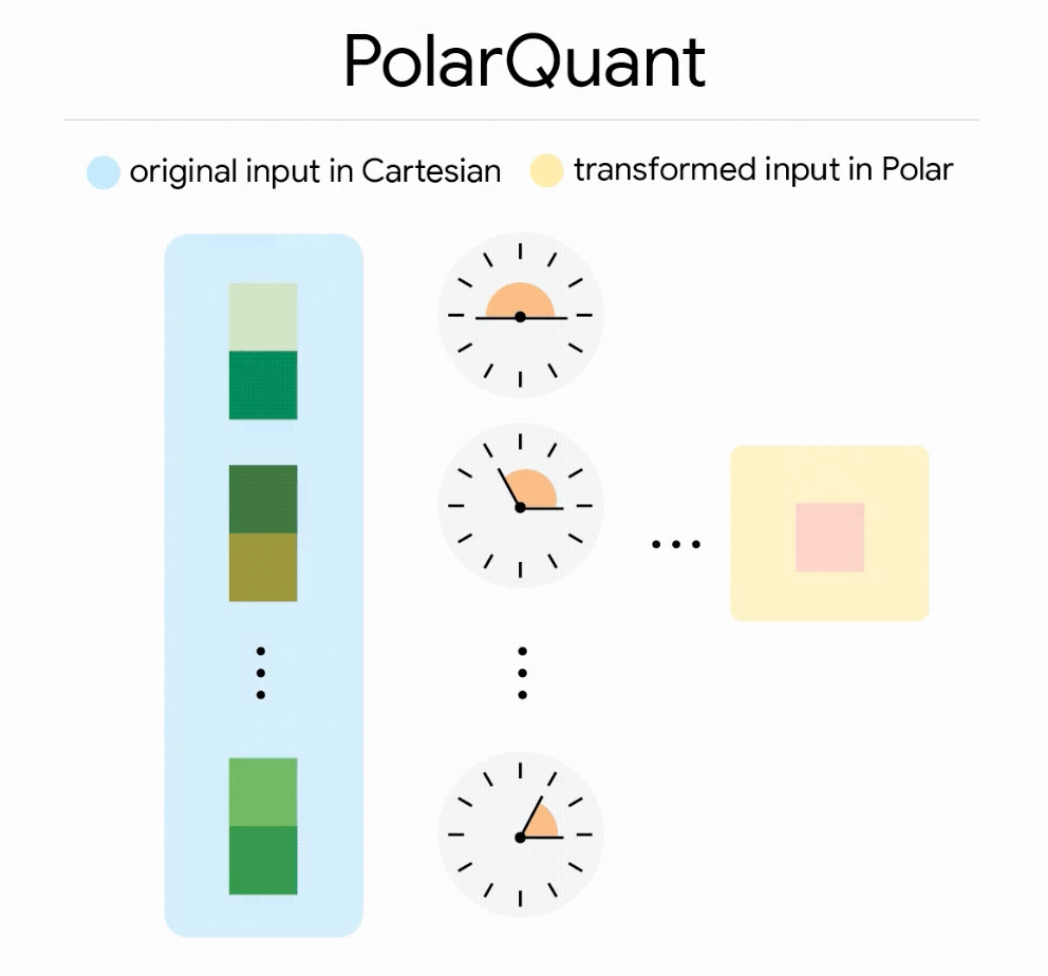
Immaginatelo come sostituire “vai 3 isolati a est e 4 a nord” con “vai 5 isolati a 37 gradi”.
Questo elimina il costoso passaggio di normalizzazione richiesto dai quantizzatori tradizionali. Poiché la distribuzione angolare nello spazio polare è altamente concentrata e prevedibile, PolarQuant può mappare i valori su una griglia fissa senza le costanti di calibrazione per blocco che aggiungono sovraccarico in ogni altro metodo.
Fase 2: QJL (Quantized Johnson-Lindenstrauss)
L’errore residuo lasciato da PolarQuant viene intercettato da un livello di correzione degli errori a 1 bit basato sulla trasformata di Johnson-Lindenstrauss.
Questa è una tecnica di riduzione della dimensionalità che preserva le distanze a coppie.
QJL utilizza un singolo bit di segno per valore e richiede un sovraccarico di memoria pari a zero. Agisce come un controllore di errori che elimina i bias, ripulendo l’approssimazione della Fase 1.
Google lo ha testato sui modelli Gemma e Mistral utilizzando LongBench, Needle-in-a-Haystack, ZeroSCROLLS, RULER e L-Eval.
TurboQuant ha ottenuto risultati a valle perfetti nelle attività needle-in-a-haystack riducendo la memoria KV di 6 volte.
Sulle GPU H100, TurboQuant a 4 bit ha offerto una velocità fino a 8 volte superiore rispetto alla baseline non quantizzata per il calcolo dei logit dell’attention.
E, cosa fondamentale: non richiede addestramento o fine-tuning, si applica al momento dell’inferenza. I vostri modelli esistenti sono appena diventati drasticamente più efficienti in termini di memoria.
Cosa significa per gli agenti
Con una compressione al livello di TurboQuant, un sistema a memoria unificata da 128 GB (come l’NVIDIA DGX Spark con il superchip GB10) può contenere oltre 4 milioni di token di KV cache.
Ancora una volta: si tratta di un sistema multi-agente in cui ogni agente può vedere tutto, sempre, senza riassunti, senza eliminazioni forzate e senza le euristiche che abbiamo usato finora per gestire il contesto.
Ciò sblocca un livello di esperienza per gli sviluppatori completamente nuovo.
Una scheda grafica da 1.600 dollari che esegue un modello da 32B quantizzato può ora produrre completamenti di codice di classe “frontier”.
Un modello da 14B su un laptop può superare o1-mini nei benchmark matematici.
Due GPU consumer possono eguagliare una scheda da data center da 25.000 dollari a un quarto del costo.
Modelli open source come Qwen3–235B-A22B superano già DeepSeek-R1 in 17 benchmark su 23, e Llama 3.3 70B eguaglia le prestazioni di livello GPT-4 in numerose attività.
Ora combiniamo questi capaci modelli aperti con la compressione di TurboQuant.
Un sistema multi-agente che prima richiedeva tre abbonamenti API separati può ora girare localmente su una singola workstation. L’impatto economico è sbalorditivo.
Inoltre, il framework MLX di Apple è ora integrato con gli acceleratori neurali dell’M5, consentendo un’inferenza quantizzata veloce nativamente su Apple Silicon.
vLLM-MLX raggiunge 464 token al secondo su M4 Max.
Hugging Face sta rilasciando versioni ottimizzate per MLX di modelli da 120B parametri con quantizzazione a 6 bit per l’inferenza locale diretta sui Mac serie M.
Il consenso della comunità è che MLX probabilmente implementerà il supporto a TurboQuant per primo, prima di llama.cpp, SGLang o vLLM, perché l’architettura di Metal è la più analoga agli algoritmi di TurboQuant e richiede meno lavoro di adattamento.
Quando ciò accadrà, un MacBook Pro diventerà una piattaforma per far girare un agente realmente capace, un sistema in grado di mantenere oltre 100.000 token di contesto, chiamare strumenti locali tramite MCP ed eseguire workflow di ragionamento multi-step, il tutto senza connessione internet.
Per gli sviluppatori che creano assistenti alla codifica, agenti CI/CD locali o automazioni sensibili alla privacy, questo è il punto di svolta.
L’hardware sta venendo incontro al software
Il superchip GB10 Grace Blackwell di NVIDIA porta sulla scrivania una GPU Blackwell con Tensor Core di quinta generazione e 128 GB di memoria coerente unificata, alimentata da una presa elettrica standard.
Supporta nativamente carichi di lavoro a precisione FP4 e FP8.
Due unità collegate con networking ConnectX possono far girare modelli da 405B parametri.
I core Cortex-X925 di ARM nella CPU Grace forniscono le prestazioni single-threaded necessarie per le parti orchestrali degli agenti (routing dei task, dispatch dei tool, parsing dei messaggi) mentre la GPU gestisce l’inferenza.
Nel frattempo, l’hardware consumer continua a migliorare.
La memoria DDR6 con larghezza di banda di 1600 GB/s è attesa con la piattaforma Epyc Venice di AMD. PCIe Gen6 raddoppia la larghezza di banda dell’interconnessione. La soglia minima dell’hardware continua ad alzarsi.
Questi sono sviluppi strabilianti.
I modelli open source stanno colmando il divario
Una pubblicazione su Nature del febbraio 2026 ha avanzato un argomento notevole:
Comprimere un gigante è più efficace che addestrare un nano.
I ricercatori hanno dimostrato che i modelli linguistici di grandi dimensioni mostrano transizioni di fase sotto compressione e che le fonti di ridondanza strutturale, numerica e algebrica sono ortogonali.
Combinando potatura (pruning), quantizzazione e decomposizione low-rank in un framework consapevole delle criticità, hanno ottenuto una compressione quasi senza perdite fino al 10% della dimensione originale del modello.
Questo si allinea perfettamente con ciò che stiamo vedendo in pratica.
I modelli open source rappresentano ora il 62,8% del mercato per numero di modelli, e la data prevista per la parità di prestazioni tra open e closed è il secondo trimestre del 2026 ai ritmi attuali.
L’ecosistema Qwen ha visto un’adozione esplosiva, diventando la famiglia di modelli più scaricata.
Il divario tra ciò che si può far girare localmente e ciò che si otterrebbe da un abbonamento API da 200 dollari al mese si restringe ogni mese.
TurboQuant riduce ulteriormente questo divario rendendo i modelli che potete far girare localmente drammaticamente più capaci.
La quantizzazione stessa si sta evolvendo rapidamente
TurboQuant è la notizia principale, ma fa parte di un più ampio rinascimento della quantizzazione:
-
GGUF i-quants (quantizzazioni a matrice di importanza) utilizzano codebook non lineari per allocare più bit ai livelli sensibili come i meccanismi di attention, consentendo a IQ4_XS di superare lo standard Q4_K_M con un ingombro minore.
-
AWQ (Activation-Aware Weight Quantization) protegge i pesi importanti osservando le distribuzioni di attivazione, ottenendo una ritenzione della qualità del 95%, la più alta tra i metodi standard. Il kernel Marlin-AWQ combina la qualità di AWQ con il massimo throughput.
-
LLM Compressor di Red Hat ha aggiunto la quantizzazione della attention e della KV cache, AutoRound (che ottimizza le decisioni di arrotondamento e i range di clipping con parametri addestrabili) e il supporto sperimentale MXFP4 per la quantizzazione a virgola mobile a 4 bit.
-
GPTQ rimane ottimizzato per le GPU con un’inferenza 5 volte più veloce rispetto a GGUF su CUDA puro con kernel Marlin.
Ognuno di questi progressi riduce il sovraccarico necessario per eseguire modelli capaci localmente.
TurboQuant si occupa della KV cache; la quantizzazione dei pesi si occupa del modello stesso. Insieme, rendono possibile l’esecuzione di modelli che sei mesi fa erano esclusivi dei data center su hardware acquistabile nei negozi di elettronica.
Costruire per il Local-First: un’architettura pratica
Se state costruendo sistemi di AI agentica oggi, ecco l’architettura che vi consiglio di considerare:
Non tutti gli agenti nel sistema hanno bisogno dello stesso modello ed è possibile instradarli in base ai requisiti di capacità:
-
Pianificazione e ragionamento complesso: Utilizzate il vostro modello locale più grande (32B–70B quantizzato) o ricorrete al cloud per compiti realmente difficili.
-
Esecuzione e uso degli strumenti: Modelli da 8B-14B gestiscono la generazione di codice, le chiamate API e l’estrazione di output strutturati con alta affidabilità.
-
Verifica e critica: Un modello più piccolo può controllare gli output rispetto agli schemi, eseguire asserzioni o segnalare errori evidenti.
-
Embedding e recupero: Modelli di embedding locali (BGE-M3, Nomic Embed) più un indice vettoriale compresso con TurboQuant.
Questo pattern Planner-Executor-Verifier si mappa naturalmente su una configurazione di inferenza locale a più livelli.
Considerazioni finali
Google ha appena dimostrato che il collo di bottiglia più costoso nell’inferenza AI può essere dissolto via software, senza bisogno di nuovo hardware.
Servono solo algoritmi migliori, applicati al momento dell’inferenza, per rendere l’hardware che già possedete drammaticamente più capace.
Le aziende che stanno costruendo per l’AI local-first proprio ora sembreranno molto lungimiranti tra poco tempo.
Articoli Bonus
7 Famiglie di LLM Locali per Sostituire Claude/Codex (per i compiti quotidiani)
Qwen 3.5 35B-A3B: Perché la tua GPU da 800$ è appena diventata una Workstation AI di classe Frontier
Ho ignorato oltre 30 alternative a OpenClaw fino a OpenFang
Garry Tan’s gstack: Far girare Claude come un team di ingegneria
MiroFish: Swarm-Intelligence con 1 milione di agenti che possono predire tutto
OpenClaw non è mai stato pronto per la produzione. NemoClaw di NVIDIA cambia tutto
MiniMax M2.7 non dovrebbe essere così vicino a Opus 4.6
I pattern agentici distribuiti dietro ogni startup vincente nel 2026
📝 Nota sulla traduzione
Questo articolo è stato tradotto automaticamente dall’inglese all’italiano utilizzando intelligenza artificiale.
L’articolo originale è disponibile su: https://agentnativedev.medium.com/turboquant-local-agent-swarms-with-4m-token-context-on-5k-desktop-cc6627666e4aTutti i diritti sui contenuti originali appartengono ai rispettivi proprietari. Questa traduzione è fornita a scopo informativo e non costituisce un’opera derivata con pretese di originalità.
Lascia un commento