Quando l’inferenza AI diventa hardware puro, i numeri cambiano drasticamente: 17.000 token al secondo, 20 volte meno costoso, 10 volte meno consumo energetico. Ecco la recensione del primo prodotto Taalas HC1.
Il problema dell’AI oggi
L’intelligenza artificiale ha dimostrato di essere “la vera rivoluzione”. In domini specifici supera già le prestazioni umane. Usata bene, è un amplificatore senza precedenti della produttività. Ma la sua adozione diffusa è ostacolata da due barriere fondamentali: alta latenza e costi astronomici.
Le interazioni con i modelli linguistici procedono a un ritmo ben lontano da quello della cognizione umana. Gli assistenti di programmazione possono riflettere per minuti, interrompendo lo stato di flusso. Nel frattempo, le applicazioni agentiche automatizzate richiedono latenze millisecondarie, non risposte al ritmo umano.
Sul fronte dei costi, distribuire modelli moderni richiede ingegneria e capitali massicci: supercomputer grandi come stanze che consumano centinaia di kilowatt, con raffreddamento a liquido, packaging avanzato, memoria stacked, I/O complesso e chilometri di cavi.
Chi è Taalas
Fondata 2,5 anni fa, Taalas ha sviluppato una piattaforma per trasformare qualsiasi modello di IA in silicio personalizzato. Dal momento in cui viene ricevuto un modello mai visto prima, può essere realizzato in hardware in soli due mesi.
I tre principi fondamentali
1. Specializzazione totale
In tutta la storia del calcolo, la specializzazione profonda è stata il percorso più sicuro verso l’efficienza estrema. L’inferenza AI è il carico di lavoro computazionale più critico che l’umanità abbia mai affrontato.
2. Fusione di memoria e calcolo
L’hardware moderno per inferenza è vincolato da una divisione artificiale: memoria da una parte, calcolo dall’altra. Taalas elimina questo confine unificando memoria e calcolo su un singolo chip.
3. Semplificazione radicale
Il risultato è un sistema che non dipende da tecnologie esotiche: niente HBM, packaging avanzato, 3D stacking, raffreddamento a liquido.
HC1: Il primo prodotto

Il primo prodotto è un Llama 3.1 8B cablato in hardware, disponibile sia come chatbot demo che come servizio API.
Le prestazioni parlano chiaro
- 17.000 token/sec per utente — quasi 10X più veloce dello stato dell’arte attuale
- 20X meno costoso da costruire rispetto alle soluzioni GPU
- 10X meno consumo energetico
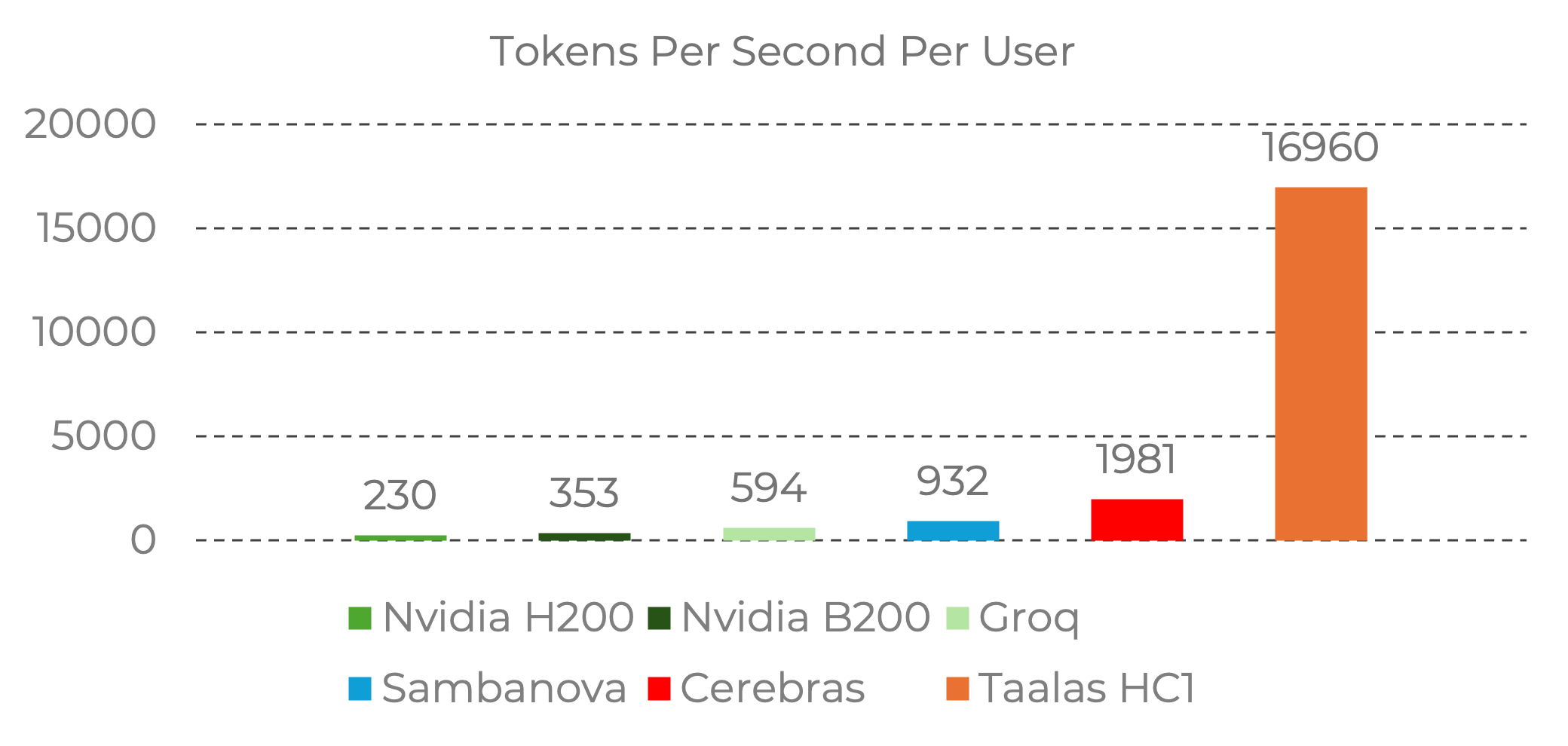
Per contesto, una Nvidia H200 raggiunge circa 1.500 token/sec/utente. Taalas HC1 spinge a 17.000.
Compromessi e roadmap
La prima generazione usa un formato dati personalizzato a 3 bit, con alcune degradazioni qualitative. La seconda generazione HC2 adotterà formati floating-point standard a 4 bit.
- Primavera 2026: Modello reasoning di medie dimensioni su HC1
- Inverno 2026: Frontier LLM su piattaforma HC2
Conclusioni
Taalas rappresenta una filosofia architetturale diversa dal mainstream: specializzazione radicale, semplificazione estrema, efficienza orders-of-magnitude superiore.
Lascia un commento