🌐 Traduzione italiana | Articolo originale: I Tried Gemma 4 On Claude Code (And Found New FREE Google Coding Beast)
Questa è una traduzione automatica realizzata con AI. I contenuti e i diritti appartengono all’autore originale.

Immagina di far girare Claude Code con il modello di coding Gemma 4 di Google su una GPU Nvidia: esiste qualcosa di meglio?
Google Gemma 4 è l’ultimo modello di coding AI che sta spopolando, quindi l’ho provato su Claude Code.
E non sono rimasto deluso.
Se hai letto il mio precedente articolo sul rilascio di Gemma 4, saprai che ero già entusiasta del nuovo modello di coding Open-Source di Google.
Ma non avevo potuto testarlo a fondo, poiché far girare il modello da 31B localmente richiede un hardware notevole.
Le cose sono cambiate questa settimana.
Ollama ora esegue Gemma 4 in cloud grazie alla partnership con NVIDIA su GPU Blackwell. Un solo comando e starai programmando con un modello che ottiene un punteggio dell’80% su LiveCodeBench e dell’89,2% su AIME 2026.
Ci stiamo lentamente allontanando dalla necessità di hardware complesso per eseguire i nuovi modelli AI, grazie a Ollama, come ho analizzato nella mia recensione della funzione Ollama Launch.
Per Gemma 4, basta digitare ollama launch claude --model gemma4:31b-cloud e sei pronto a partire.
Ho trascorso alcune ore testando questa combinazione:
-
La finestra di contesto da 256K gestisce codebase di grandi dimensioni senza necessità di suddivisione (chunking).
-
Il function calling nativo funziona perfettamente con i workflow agentici di Claude Code.
-
E la licenza Apache 2.0 significa nessuna restrizione.
In questo articolo, ti guiderò attraverso la configurazione, eseguirò test di programmazione reali e condividerò la mia onesta esperienza con questa combinazione.
Solo un rapido promemoria:
Se sei nuovo ai miei contenuti, ti sei perso un anno di aggiornamenti su Claude Code, in cui ho coperto ogni nuova funzionalità, suggerimento e trucco. Consulta qui l’elenco completo dei tutorial su Claude Code. Seguimi qui su Medium e iscriviti alla mia newsletter Claude Code Masterclass per non perdere i nuovi aggiornamenti.
Gemma 4: Progettata perfettamente per Claude Code

Google ha sviluppato Gemma 4 partendo dalla stessa ricerca alla base di Gemini 3. La differenza è che puoi eseguirla tu stesso, localmente o tramite Ollama Cloud.
Per gli utenti di Claude Code:
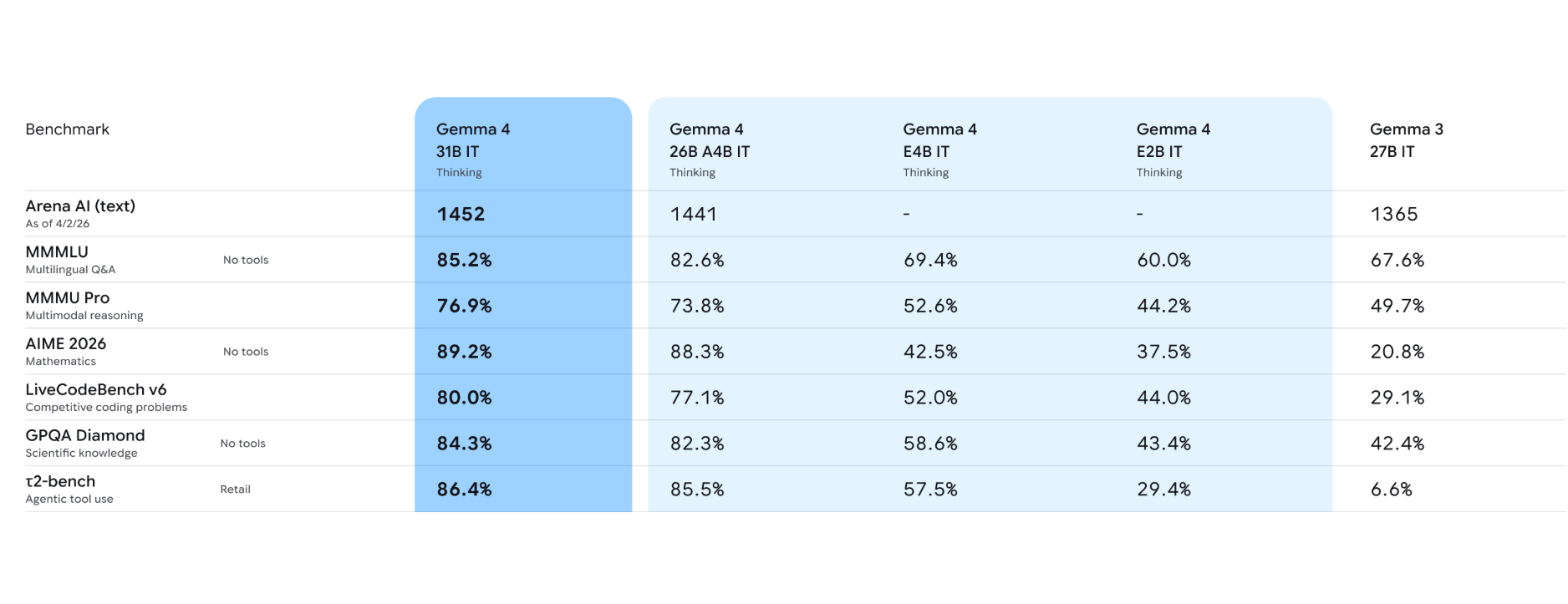
Il modello da 31B presenta benchmark di tutto rispetto:
-
LiveCodeBench v6: 80% — lo stato dell’arte (SOTA) open-source per il coding.
-
AIME 2026: 89,2% — rispetto al 20,8% di Gemma 3 nello stesso test.
-
Codeforces ELO: 2150 — livello da programmazione competitiva.
-
MMLU Pro: 85,2% — eccellente ragionamento generale.
Per contestualizzare, questi numeri fino a pochi mesi fa erano esclusiva dei modelli proprietari di classe “frontier”.
Finestra di Contesto
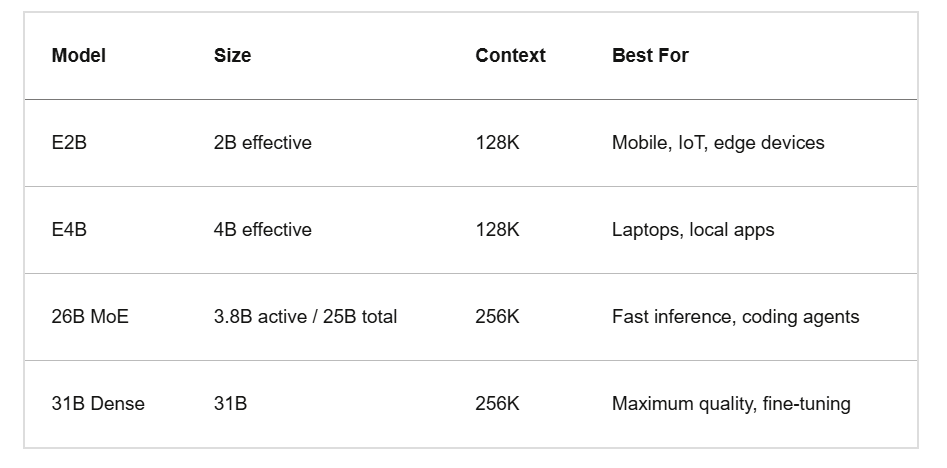
I modelli da 31B e 26B supportano 256K token. I modelli edge più piccoli, E2B ed E4B, arrivano fino a 128K.
In pratica, puoi passare interi codebase in un singolo prompt senza suddivisioni. Il refactoring multi-file diventa molto più fluido quando il modello può vedere tutto contemporaneamente.
Function Calling Nativo
Gemma 4 supporta l’uso strutturato degli strumenti (tool use) in modo nativo.
Questo è fondamentale per i workflow agentici di Claude Code; il modello può richiamare strumenti esterni, API ed eseguire operazioni multi-step in modo rapido e semplice.
Licenza Apache 2.0
A differenza delle precedenti versioni di Gemma con licenze personalizzate,
Gemma 4 viene rilasciata sotto licenza Apache 2.0. Non ci sono restrizioni sull’uso commerciale, il fine-tuning o l’implementazione. Termini simili a Qwen e alla maggior parte dell’ecosistema open-weight.
Ollama Cloud + Gemma 4 + Claude Code
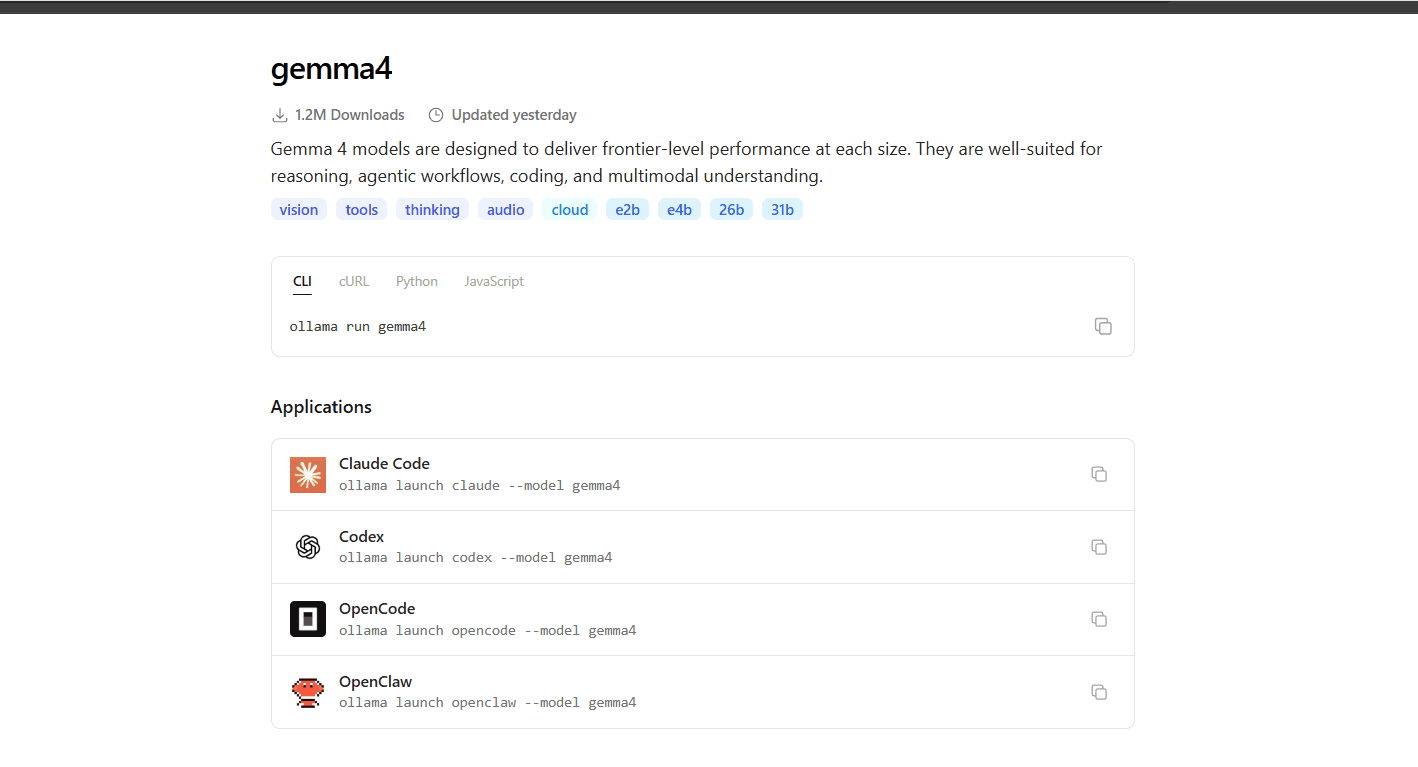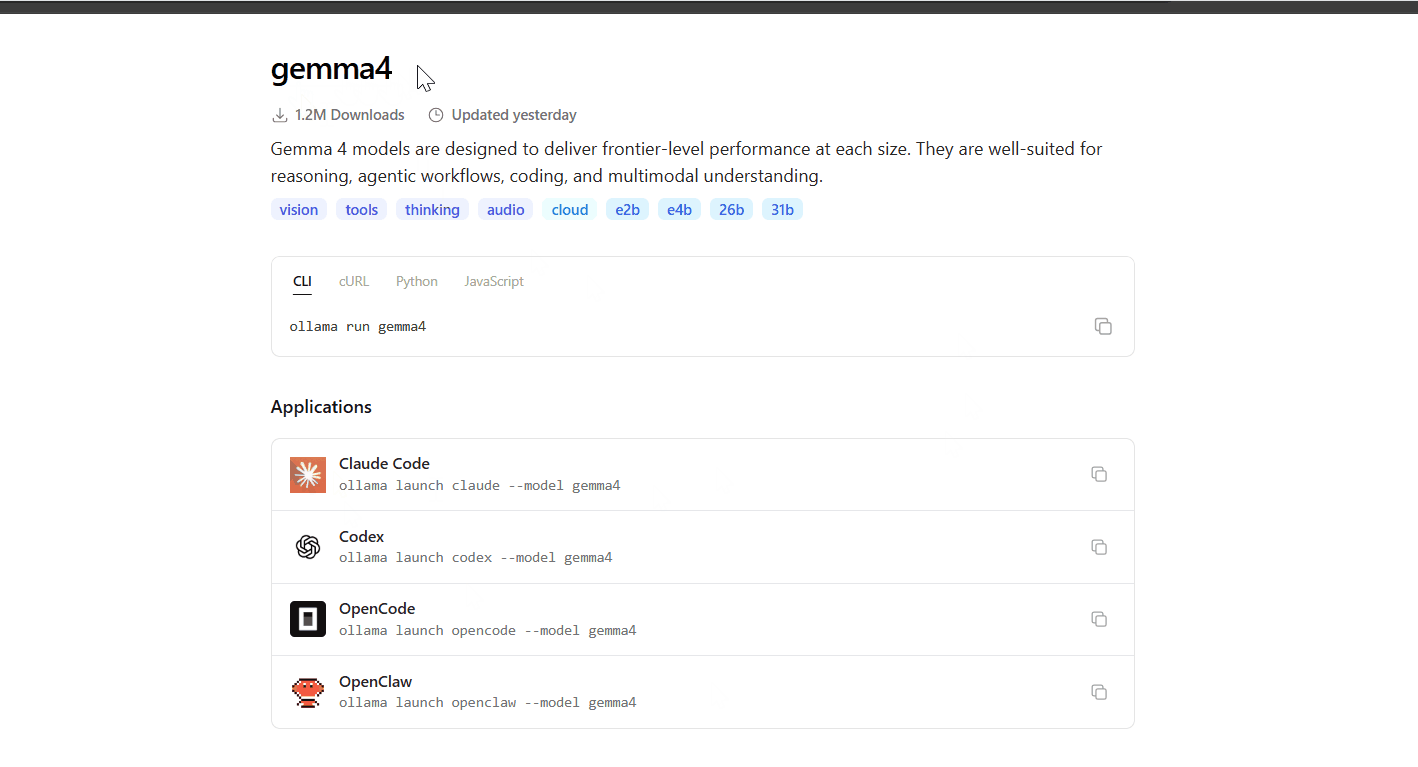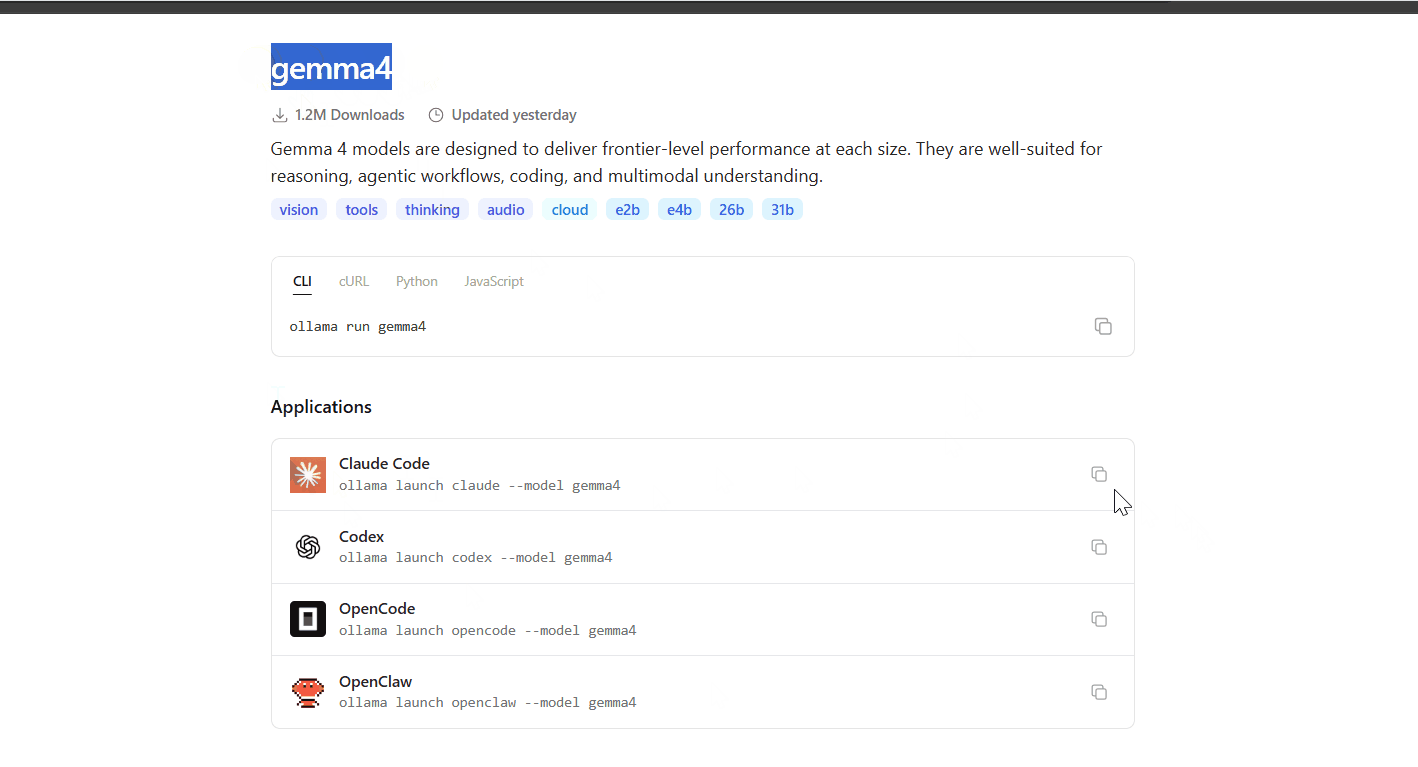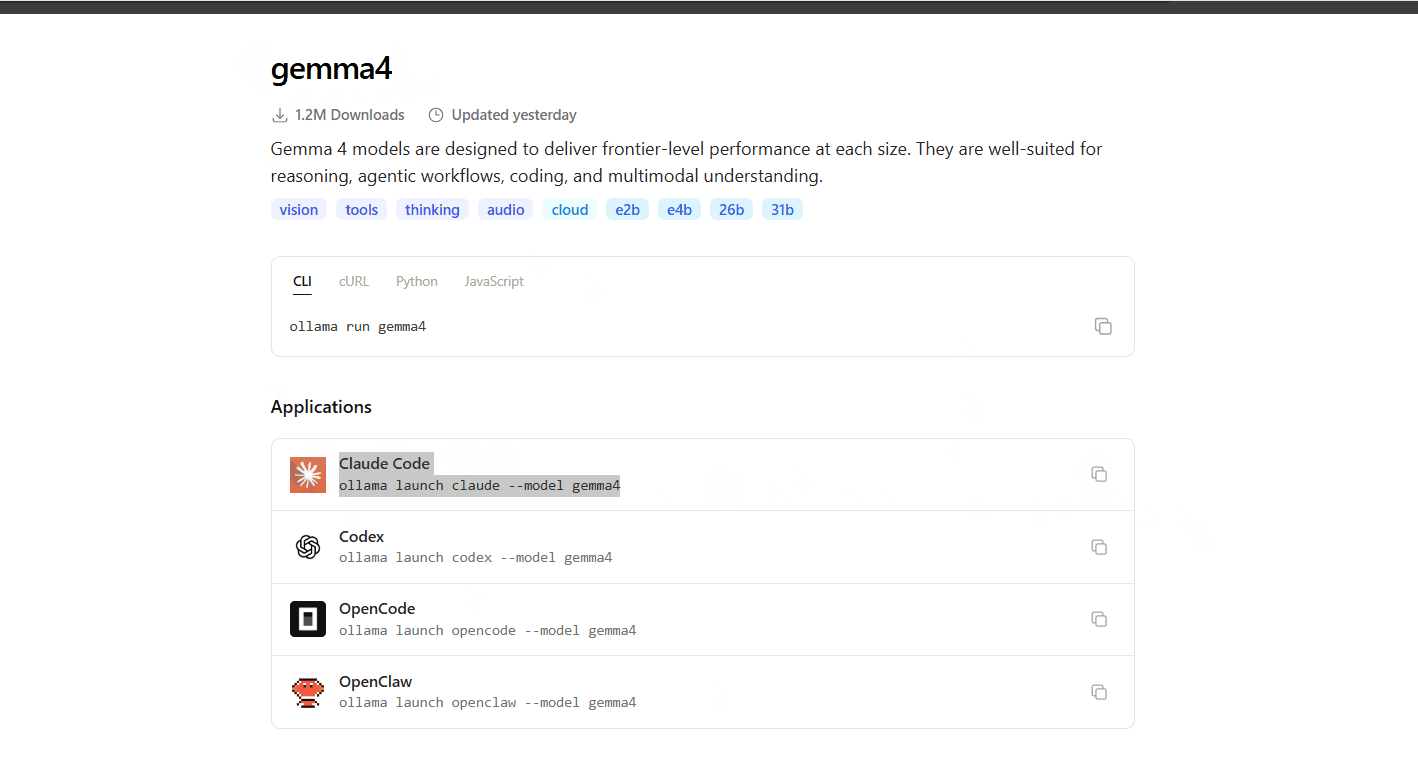
Questo è esattamente ciò di cui hanno bisogno i programmatori che non dispongono di GPU di fascia alta.
Eseguire il modello da 31B localmente richiede oltre 20GB di VRAM. Il modello 26B MoE ne richiede 18GB. Non tutti dispongono di tale hardware.
Ollama ha collaborato con NVIDIA per far girare Gemma 4 su GPU Blackwell nel cloud. Ottieni l’intero modello da 31B senza i requisiti hardware.
La configurazione richiede un solo comando:
ollama launch claude --model gemma4:31b-cloud
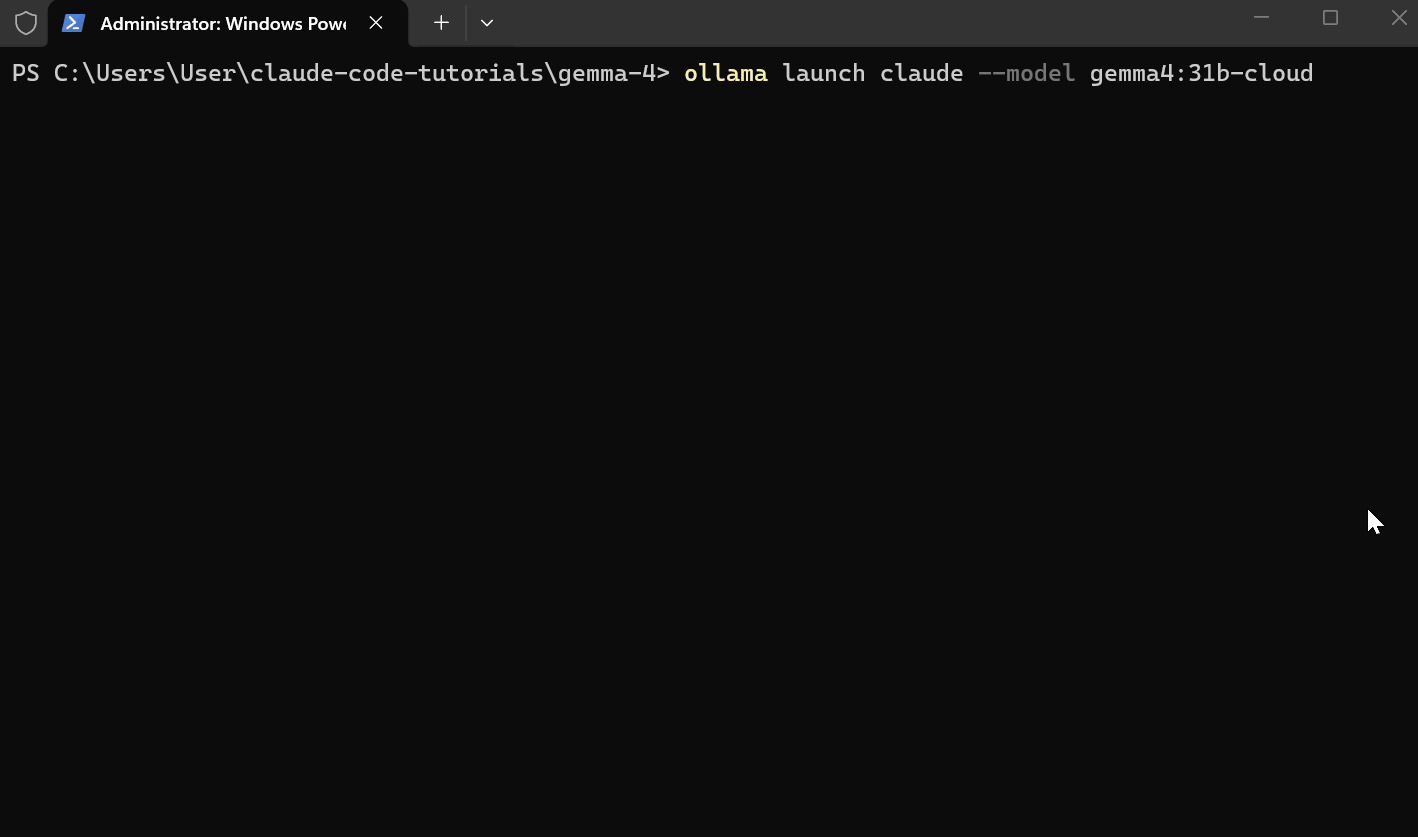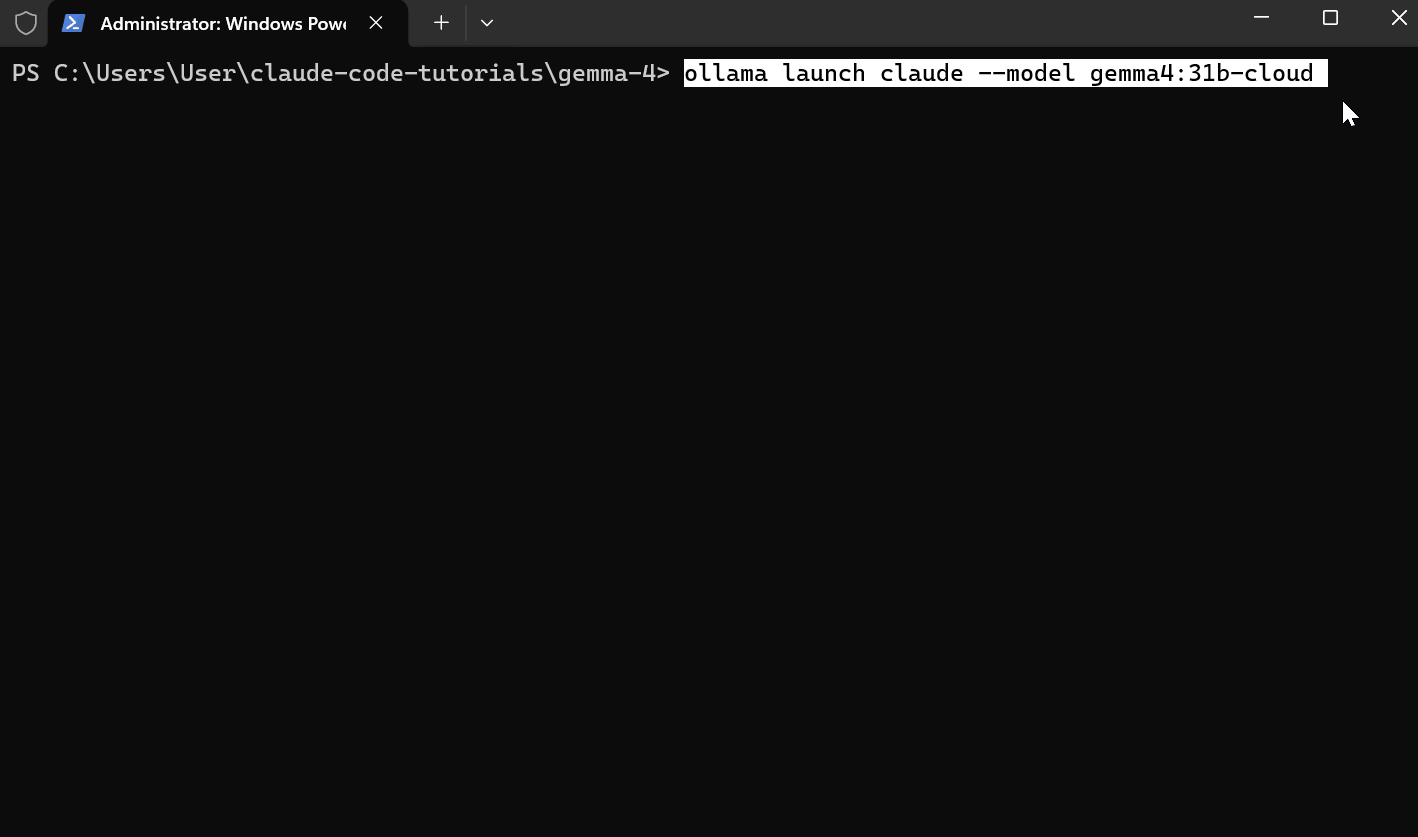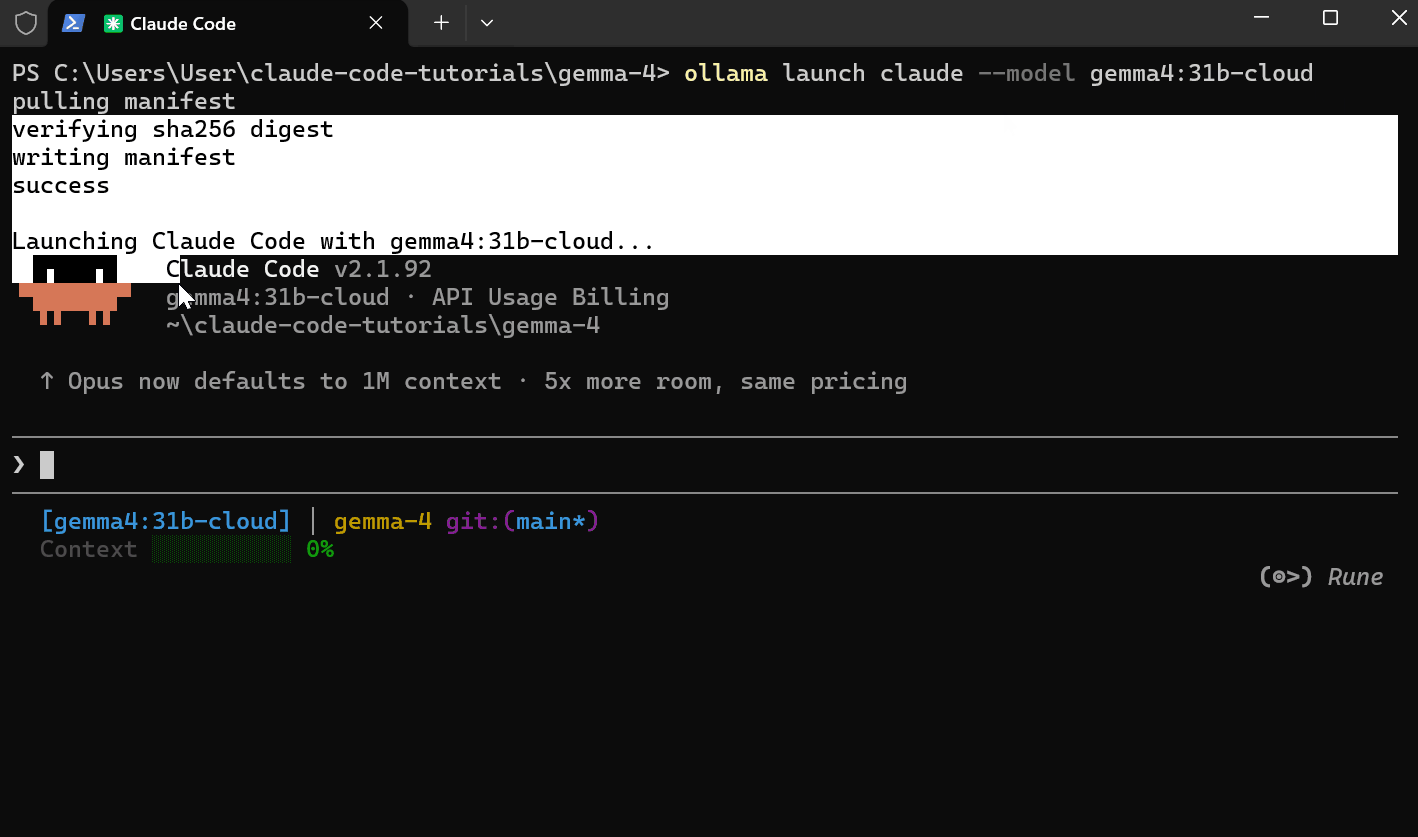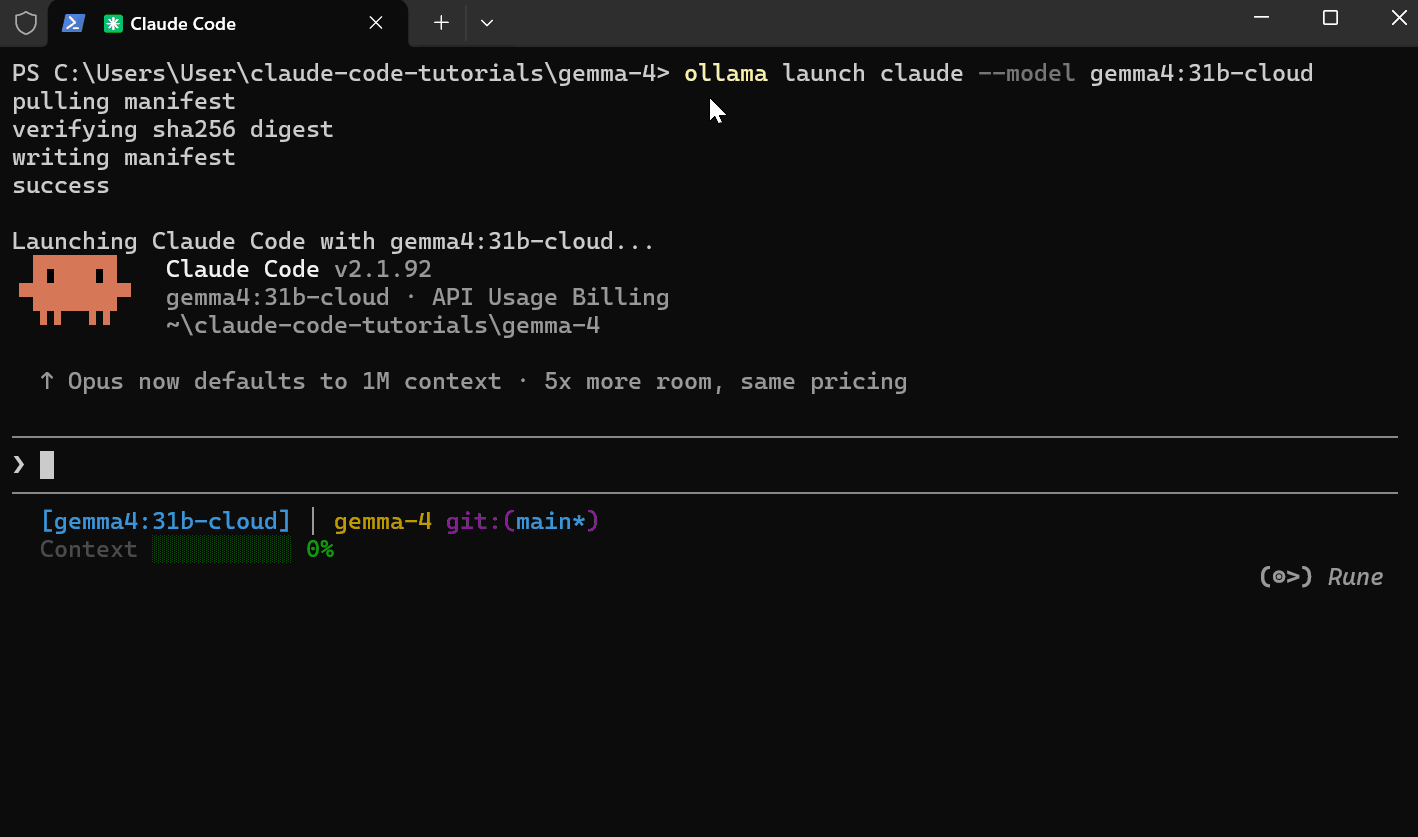
I modelli cloud girano automaticamente con la massima lunghezza di contesto. Non è necessario configurare le impostazioni del contesto come faresti per i modelli locali.
Configurazione di Gemma 4 con Claude Code
Gemma 4 è disponibile su Ollama con integrazione cloud. Basta un comando per iniziare.
Prerequisiti
Prima di iniziare, assicurati di avere:
-
Ollama v0.15+ installato
-
Claude Code v2.1+ installato
-
Un account Ollama Cloud
Passaggio 1: Installa Ollama
Se non hai installato Ollama:
Mac:
brew install ollama
Linux:
curl -fsSL https://ollama.com/install.sh | sh
Windows: Scarica l’installer da ollama.com ed eseguilo.
Verifica l’installazione:
ollama --version

Passaggio 2: Installa Claude Code
Se hai già installato Claude Code, passa al Passaggio 3.
Mac/Linux:
curl -fsSL https://claude.ai/install.sh | bash
Windows PowerShell:
irm https://claude.ai/install.ps1 | iex
Verifica l’installazione:
claude --version
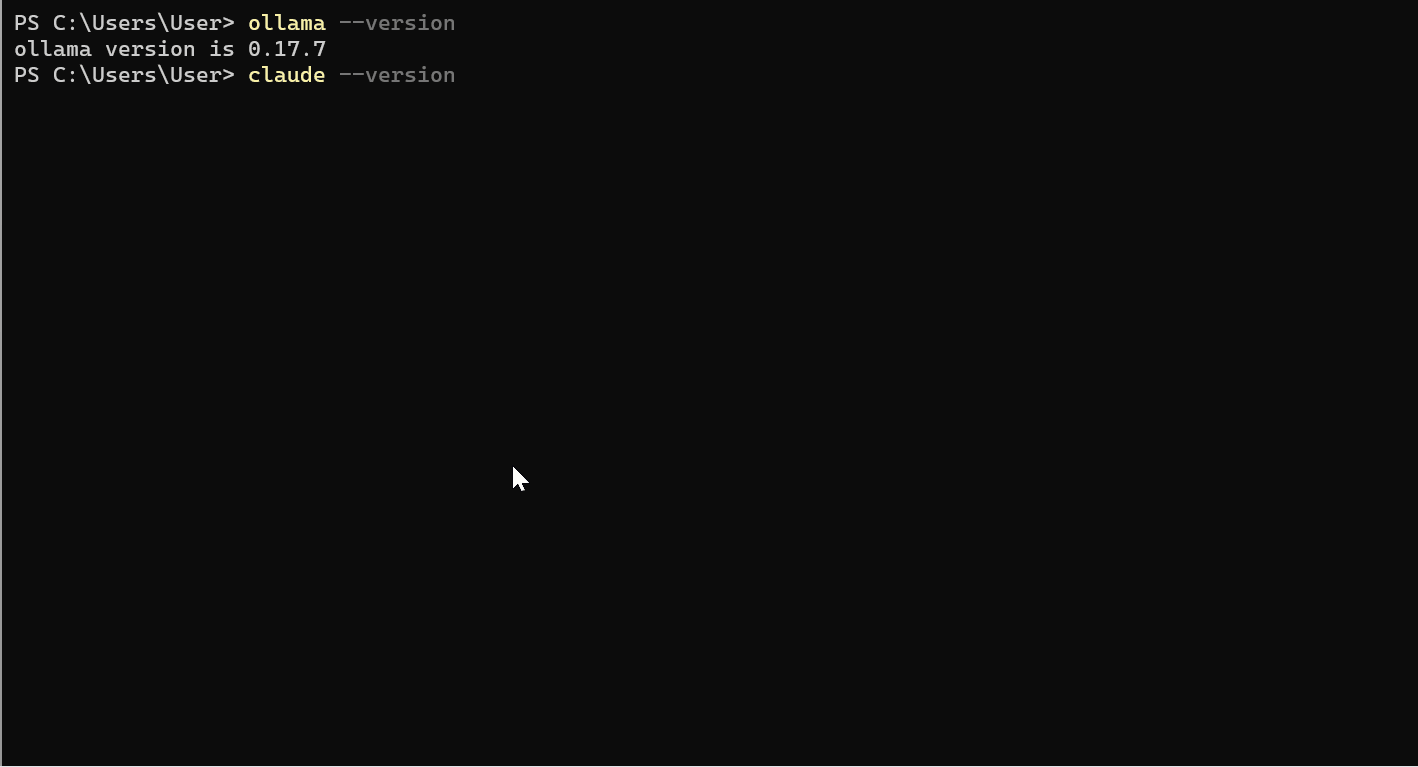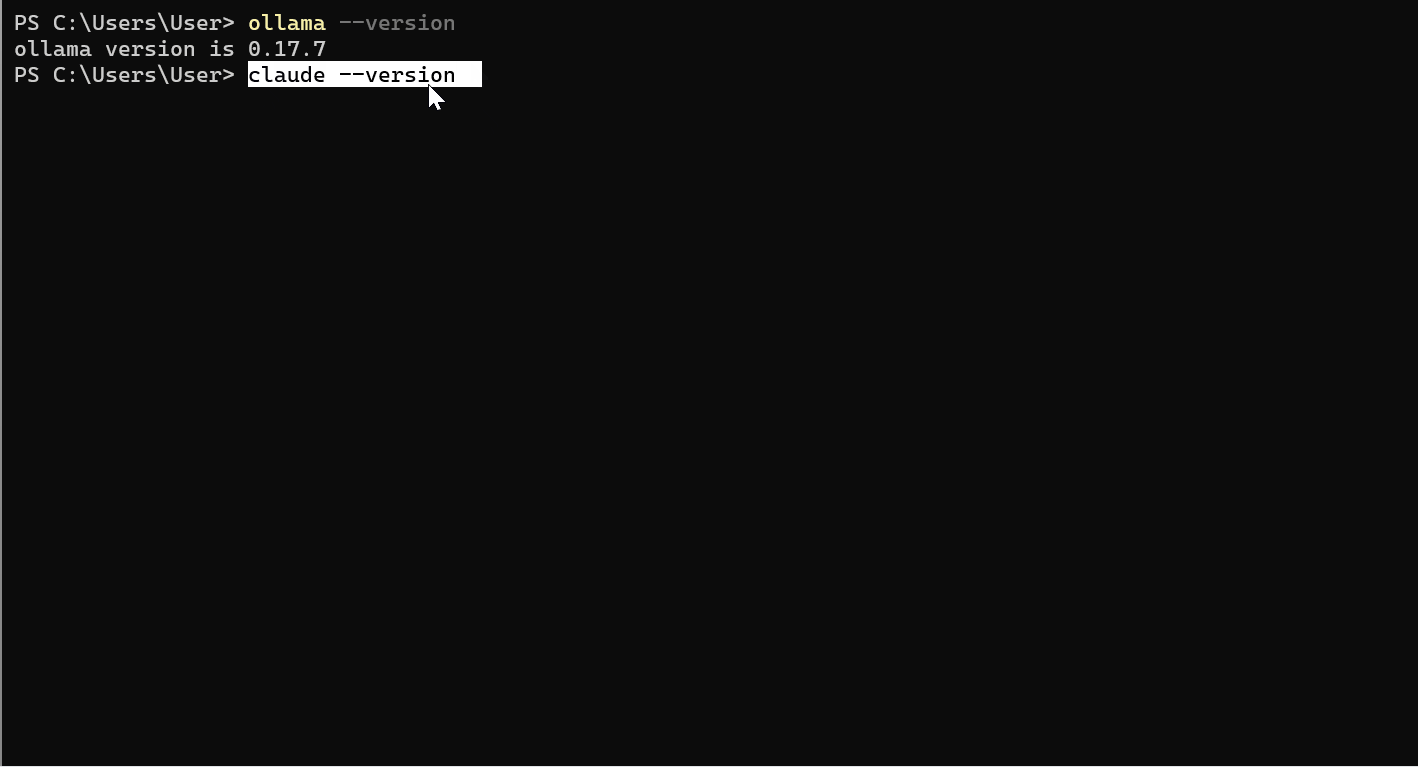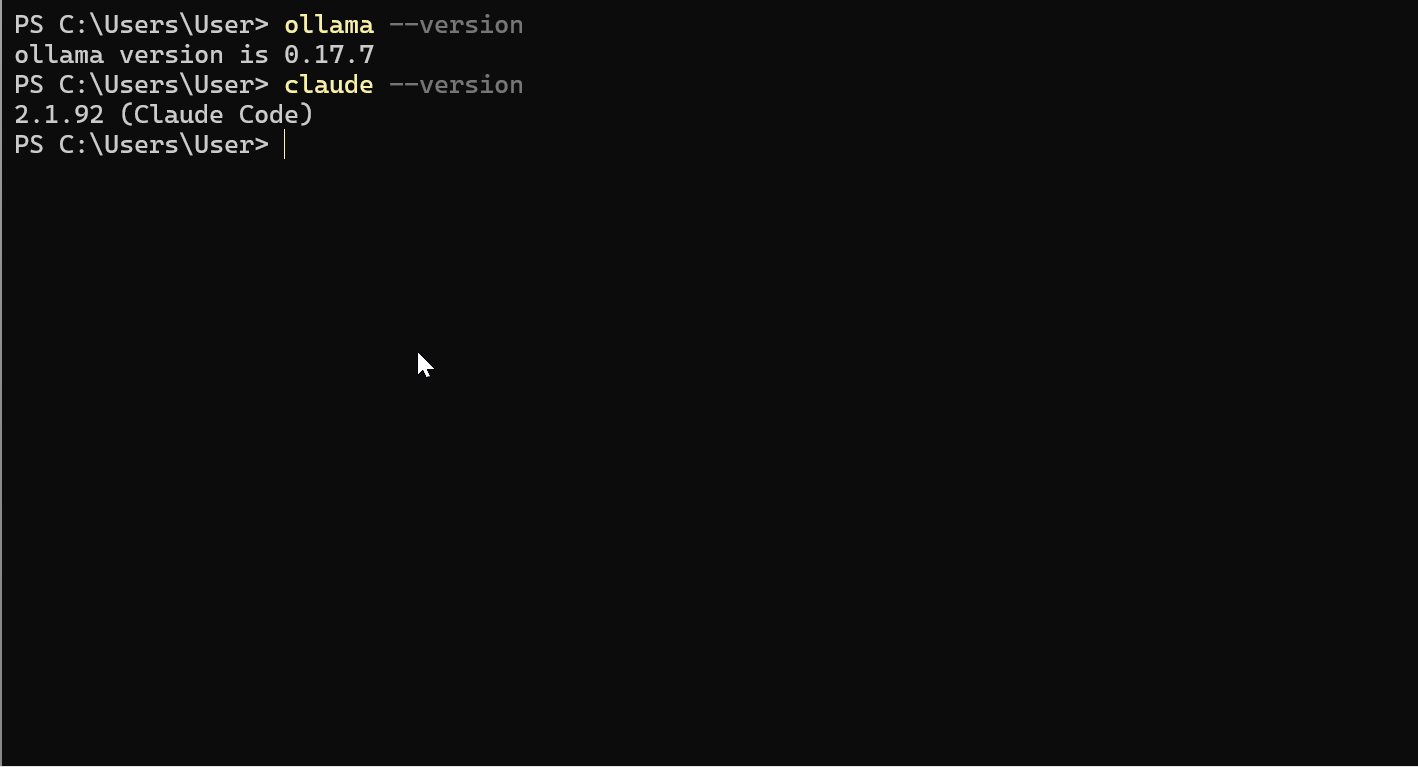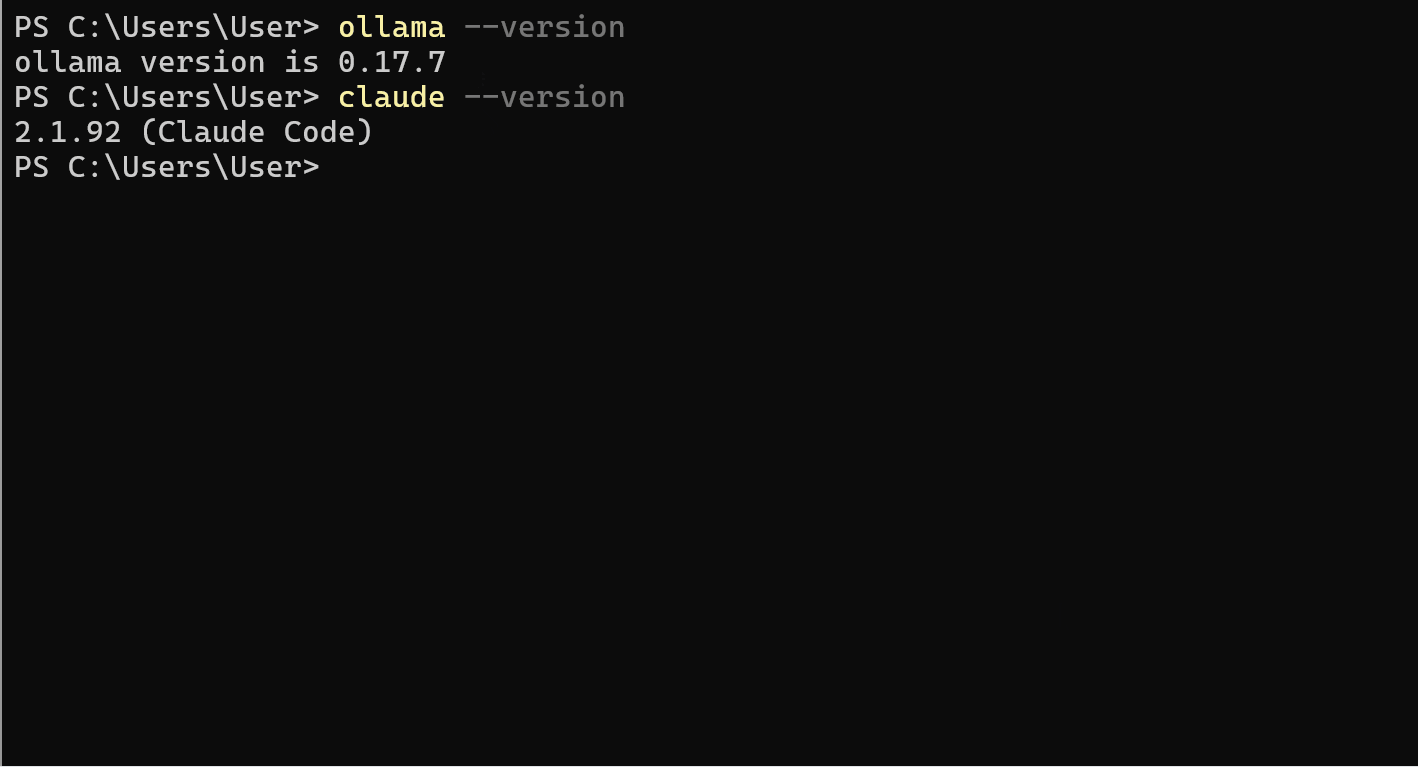
Dovresti vedere la versione 2.1.92 o successiva.
Passaggio 3: Scarica il modello Gemma 4 Cloud
ollama pull gemma4:31b-cloud
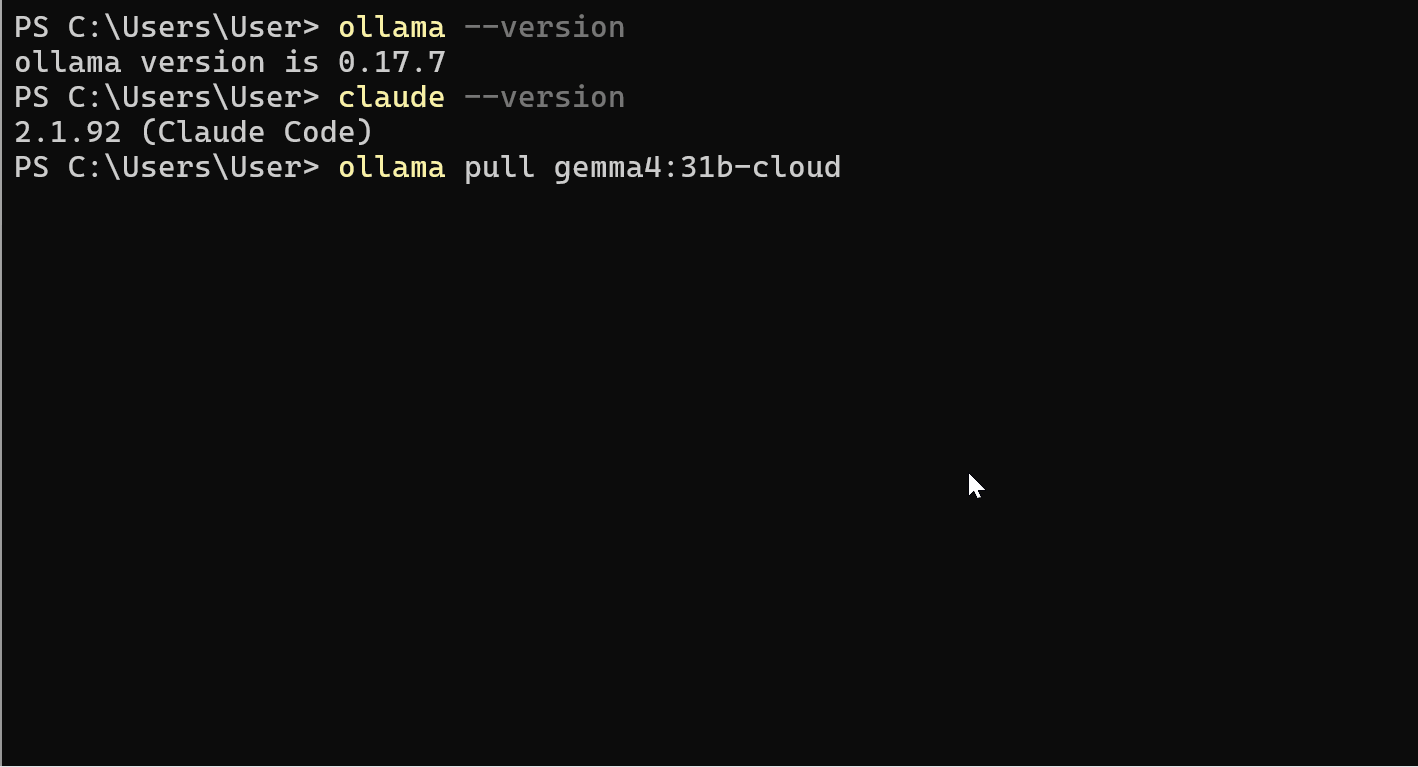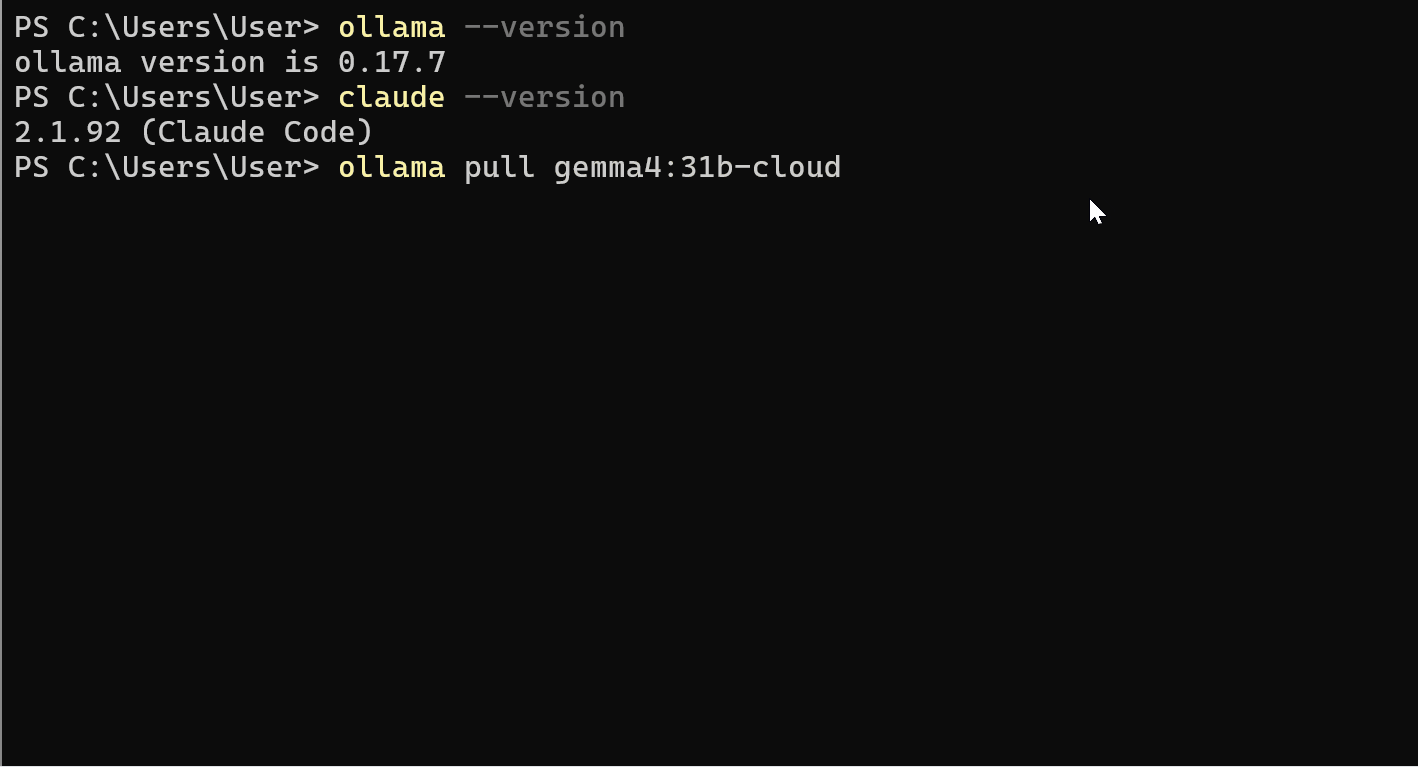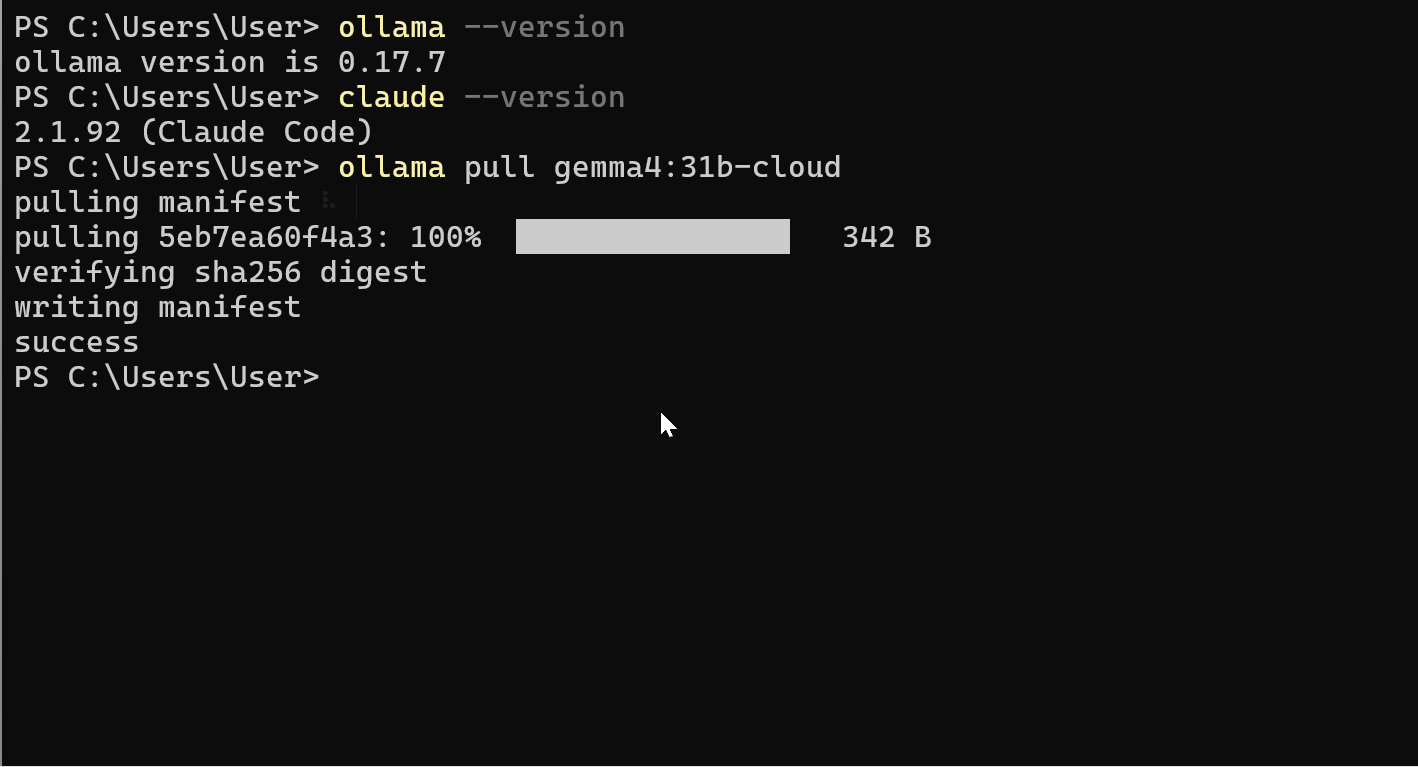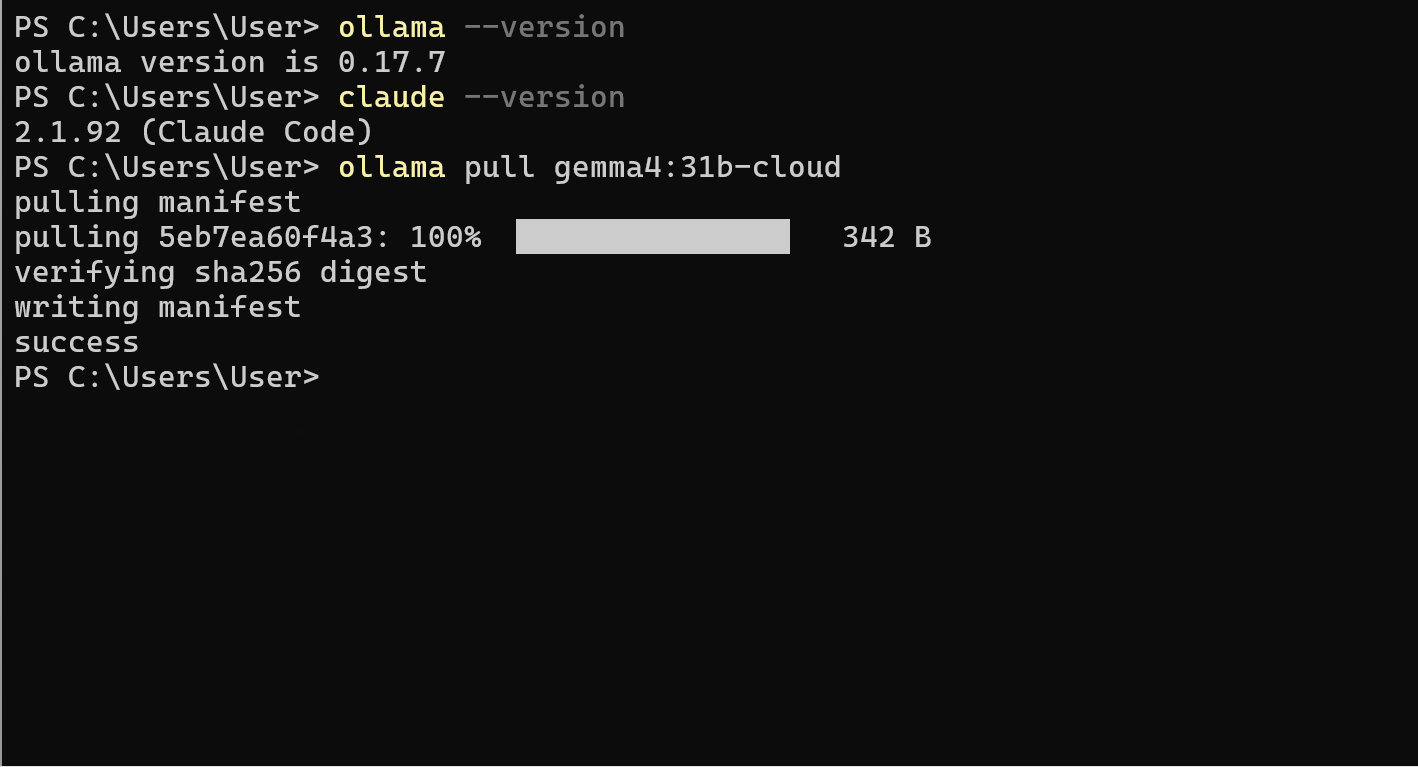
I modelli cloud si registrano rapidamente poiché l’inferenza avviene in remoto sulle GPU NVIDIA Blackwell.
Passaggio 4: Avvia Claude Code con Gemma 4
Ecco il comando:
ollama launch claude --model gemma4:31b-cloud
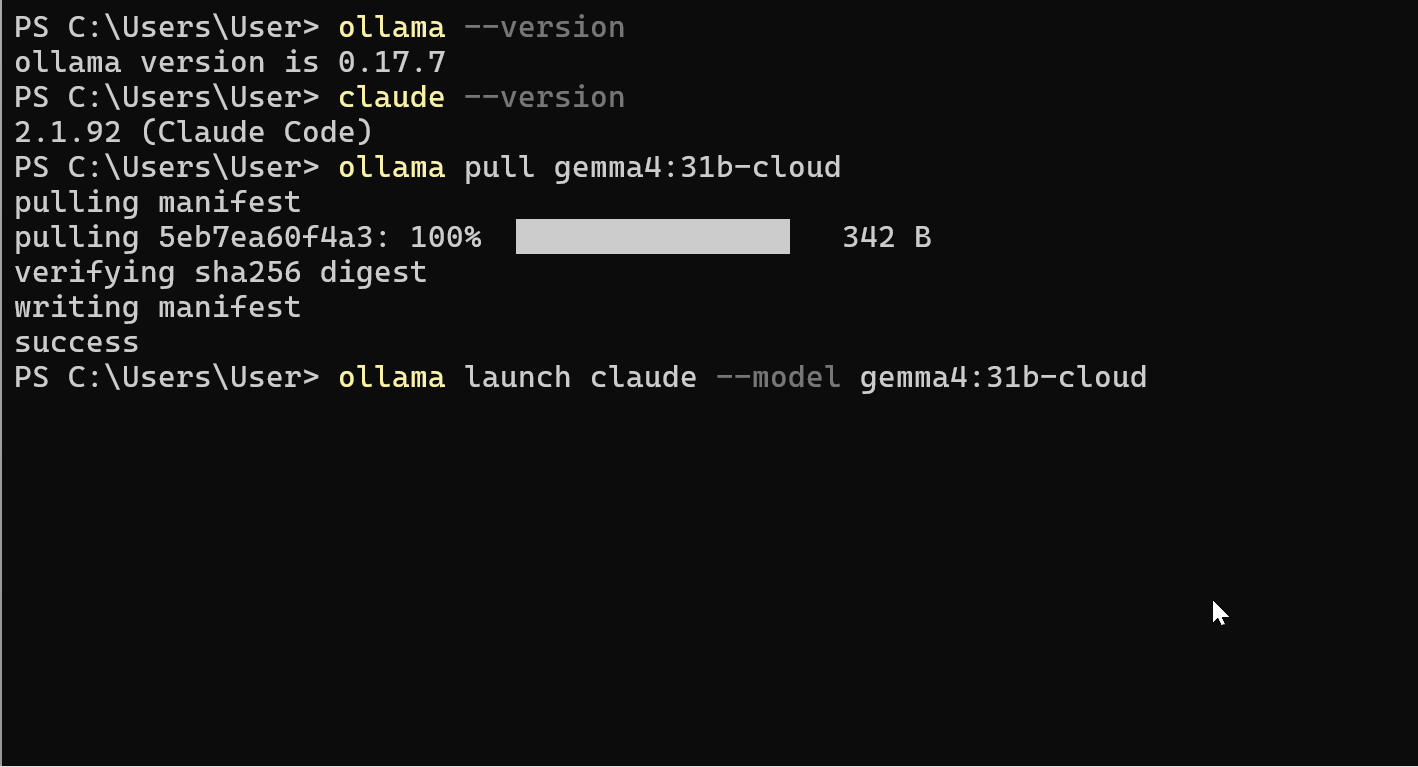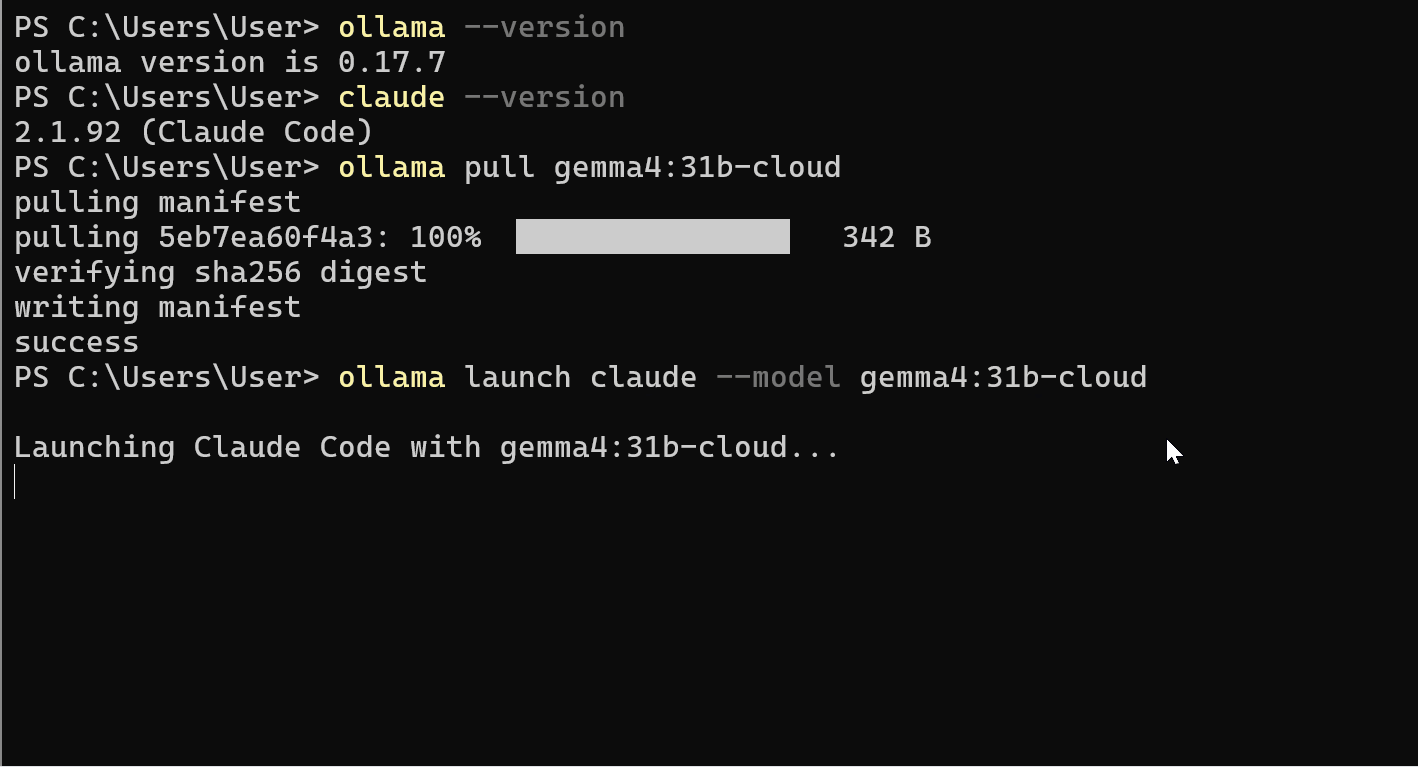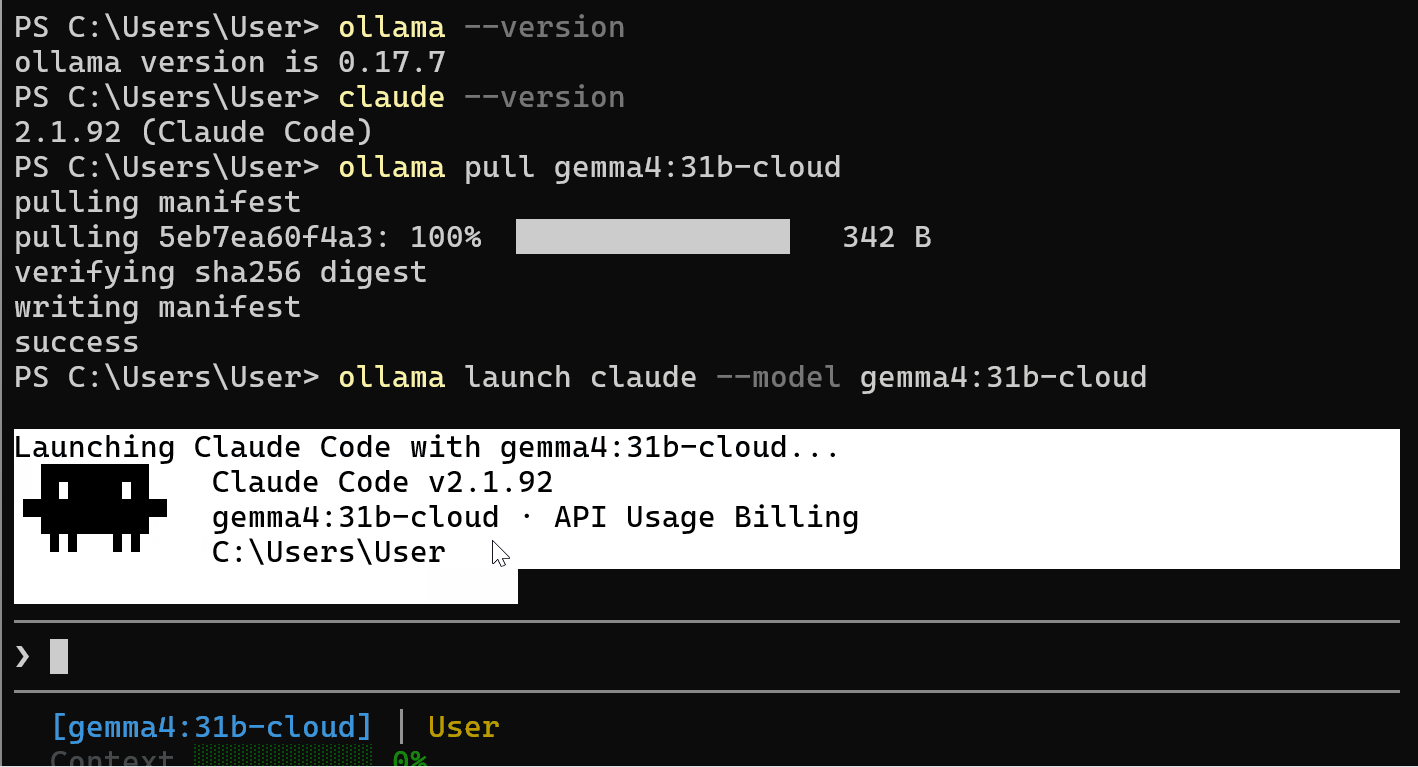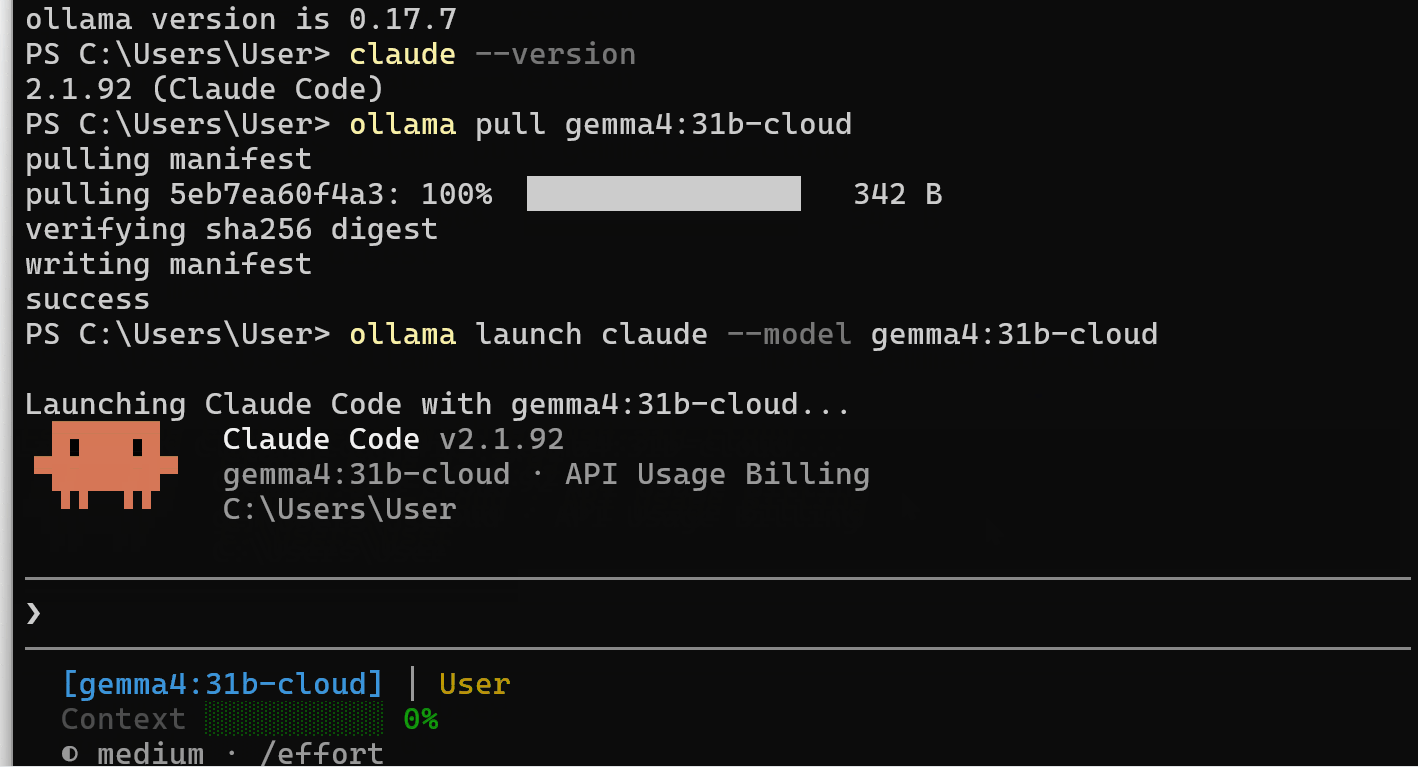
Ollama gestisce la configurazione delle API dietro le quinte. Non è necessario esportare variabili d’ambiente o impostare manualmente URL di base.
Passaggio 5: Verifica la configurazione
Una volta che Claude Code è in esecuzione, controlla lo stato:
/status

Dovresti vedere:
-
Model: gemma4:31b-cloud
-
Anthropic base URL: http://127.0.0.1:11434
-
Auth token: ANTHROPIC_AUTH_TOKEN
Passaggio 5: Prompt di test
Dopo aver confermato che stai utilizzando il modello Gemma 4, puoi eseguire un prompt di test:

Comprendere il Modello Cloud
Gemma 4 su Ollama Cloud viene eseguito in remoto, non localmente.
Ecco cosa significa:
-
gemma4:31b-cloud: Gira su GPU NVIDIA Blackwell tramite il cloud di Ollama.
-
Finestra di contesto da 256K: Lunghezza di contesto completa, nessuna configurazione necessaria.
-
Nessuna GPU locale richiesta: Il lavoro pesante avviene sui server di NVIDIA.
Il tuo codice e i tuoi prompt vengono inviati al cloud per l’elaborazione. Tienilo a mente se stai lavorando su codebase proprietari.
Opzione Modello Locale
Se disponi dell’hardware necessario e preferisci l’inferenza locale:
# Per laptop (10GB+ VRAM)
ollama pull gemma4:e4b
ollama launch claude --model gemma4:e4b
# Per workstation (18GB+ VRAM)
ollama pull gemma4:26b
ollama launch claude --model gemma4:26b
# Per la massima qualità (20GB+ VRAM)
ollama pull gemma4:31b
ollama launch claude --model gemma4:31b
I modelli locali offrono privacy e latenza zero, ma richiedono una quantità significativa di VRAM.
Per una guida completa su Ollama Launch, consulta il mio articolo precedente: I Tested (New) Ollama Launch For Claude Code, Codex, OpenCode (No More Configs)
Test Pratici di Programmazione
Ho eseguito alcuni test per vedere come si comporta Gemma 4 in scenari di coding reali.
Test 1: Creazione di un’app complessa (One-Shot)
Ho usato lo stesso approccio dei miei precedenti articoli su GLM.
Ecco il mio prompt:
Costruiscimi un task tracker in tempo reale con:
- Aggiunta di task con titolo, priorità, scadenza e tag
- Dashboard che mostra i task per priorità (grafico a barre) e tasso di completamento (anello di progresso)
- Filtro dei task per priorità, tag e intervallo di date
- Segna come completato con animazione
- Interruttore modalità scura/chiara
- Interfaccia utente pulita e moderna con Tailwind
- Salvataggio nel local storage
Gemma 4 ha attivato la modalità autopilot e ha utilizzato un agente di pianificazione per scomporre l’attività prima di scrivere qualsiasi riga di codice.
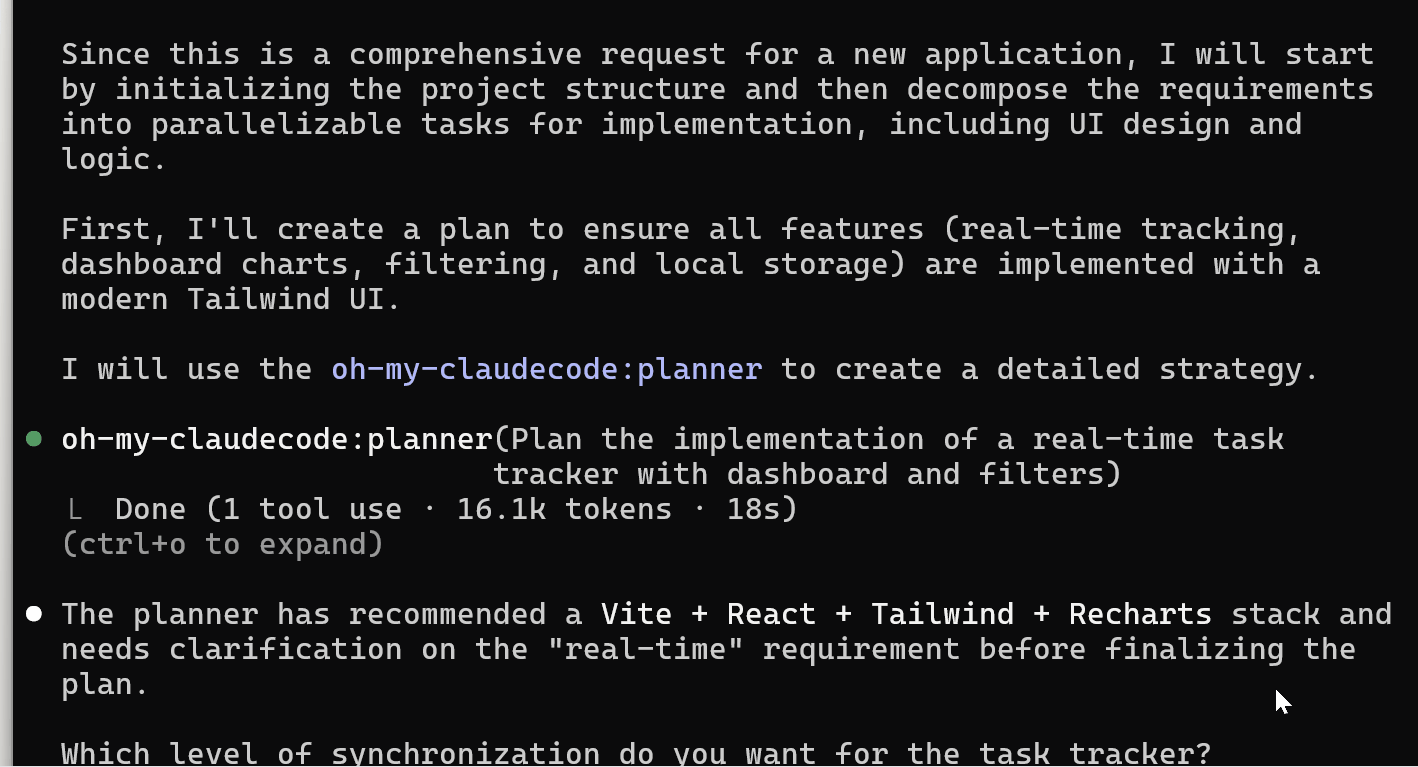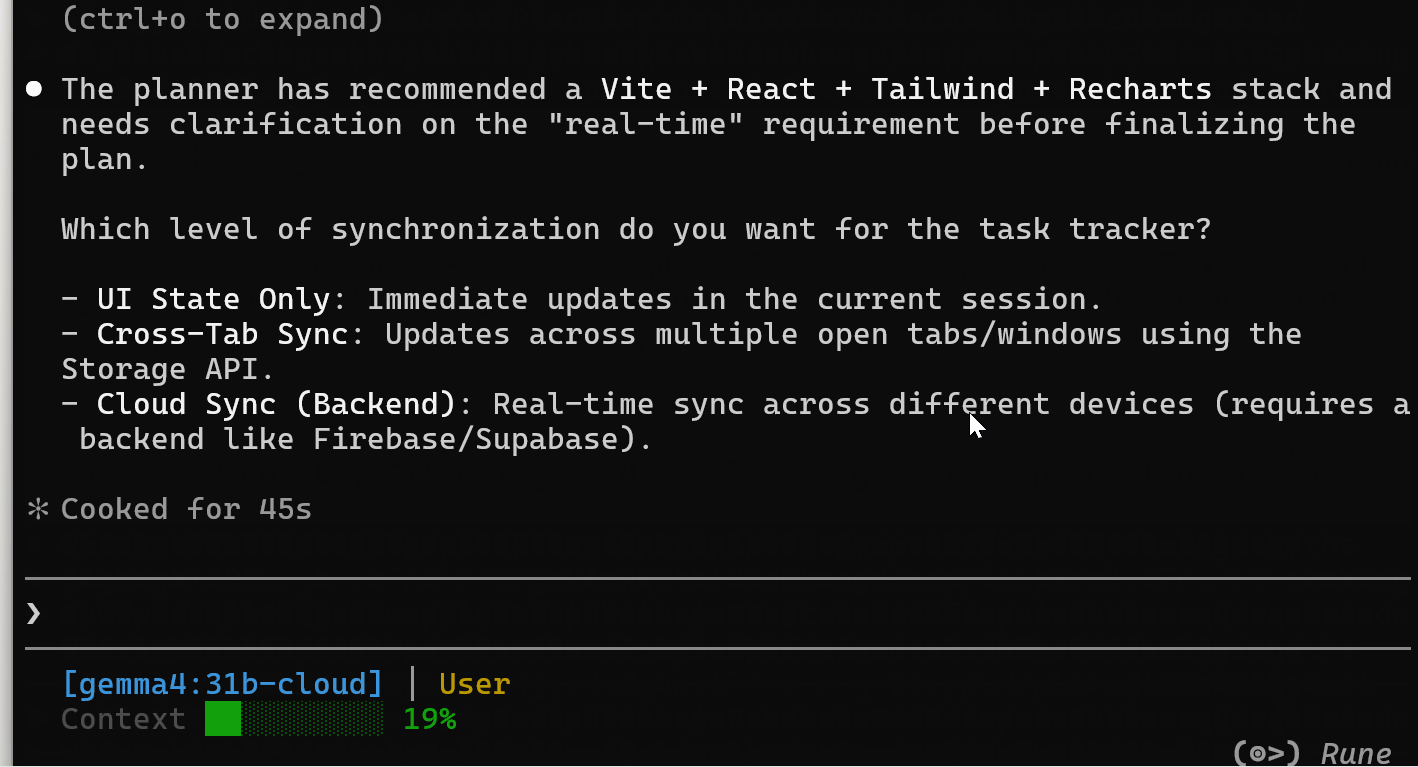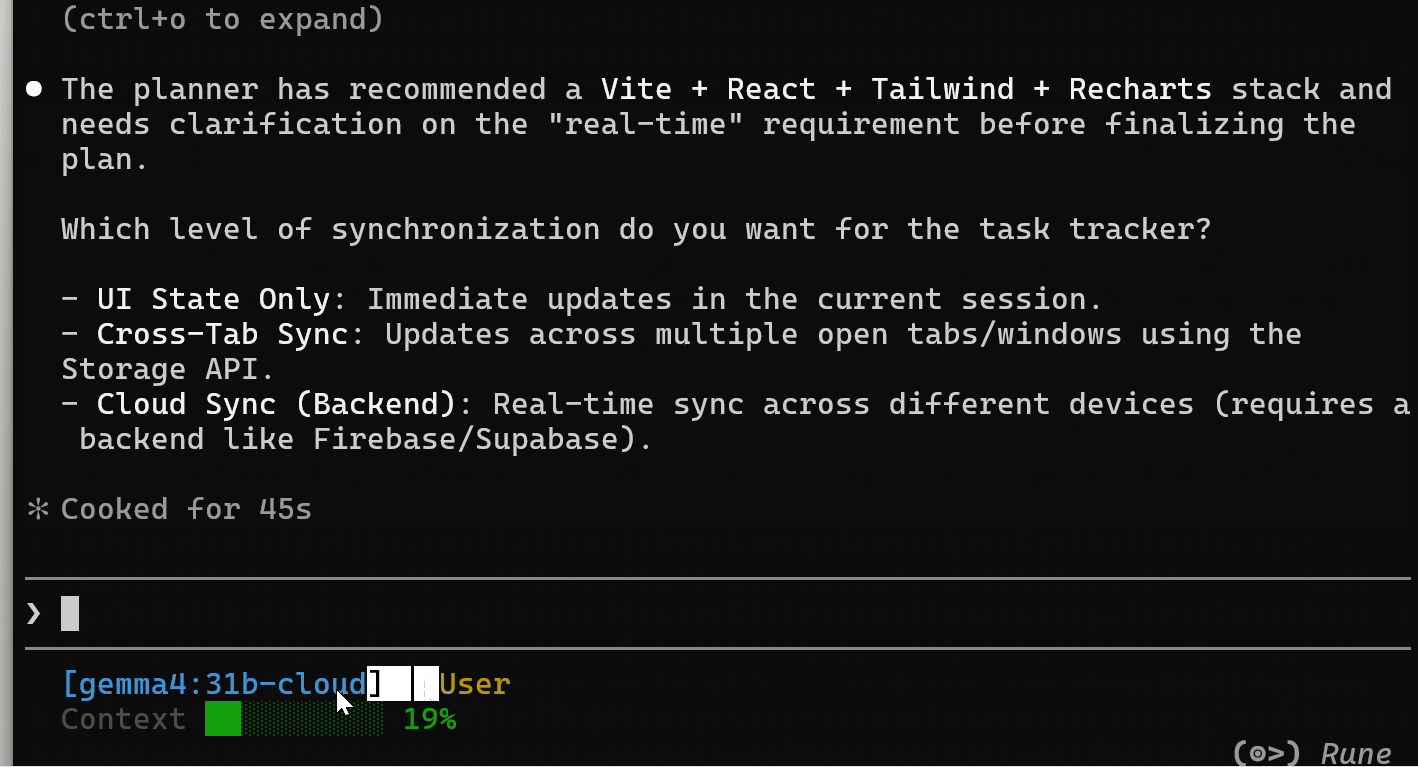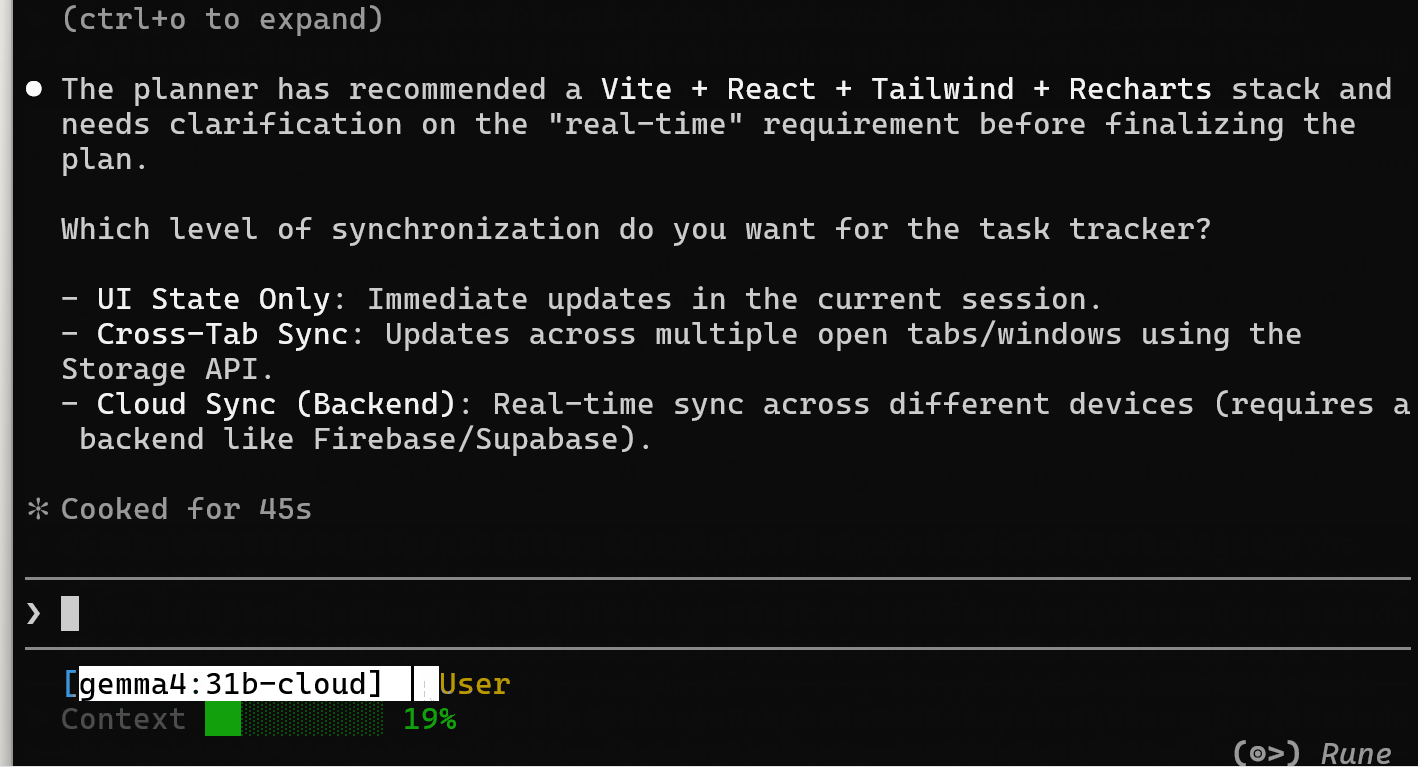
Ha scelto lo stack Vite + React + Tailwind + Recharts. Poi mi ha posto una domanda chiarificatrice su cosa intendessi per “tempo reale”: solo stato della UI, sincronizzazione tra schede o sincronizzazione cloud.

Questo non era qualcosa che avevo chiesto esplicitamente. Il modello ha suddiviso una richiesta complessa in fasi e ha chiesto chiarimenti prima di procedere.
Dopo aver selezionato “Solo stato della UI”, Gemma 4 ha sviluppato l’intera applicazione.
-
I componenti erano ben organizzati.
-
I grafici venivano renderizzati correttamente.
-
La modalità scura ha funzionato al primo colpo.
Risultato one-shot per un’app funzionante con grafici, filtri, animazioni e persistenza nel local storage. La struttura del codice era pulita e le classi Tailwind seguivano pattern coerenti.
Test 2: Operazioni Multi-File
La finestra di contesto da 256K dovrebbe aiutare nel refactoring multi-file.
Ho chiesto a Gemma 4 di rifattorizzare un progetto JavaScript esistente in TypeScript:
Rifattorizza questo progetto per usare TypeScript invece di JavaScript.
Aggiorna tutti i file, aggiungi i tipi corretti e assicurati che tutto funzioni ancora.
Gemma 4 ha mantenuto il contesto in tutti i file. Quando ha aggiornato le definizioni dei tipi in un file, ha ricordato quei tipi durante l’aggiornamento degli import negli altri file.
Test 3: Operazioni da Terminale
Ho testato la capacità di programmazione basata sul terminale:
Configura un nuovo progetto Node.js con TypeScript, ESLint, Prettier e Jest.
Configura correttamente tutti i file di configurazione e aggiungi gli script npm per dev, build, test e lint.
I file tsconfig.json, .eslintrc, .prettierrc e jest.config.js hanno funzionato tutti insieme senza conflitti.
Osservazioni
Alcuni elementi sono emersi chiaramente durante i test:
-
Pianificazione Autopilot: Gemma 4 scompone compiti complessi in fasi. Utilizza agenti di pianificazione per analizzare i requisiti prima di scrivere il codice.
-
Domande Chiarificatrici: Il modello pone domande intelligenti quando i requisiti sono ambigui.
-
Qualità del Codice: Il codice generato è pulito e i componenti sono ben organizzati.
-
Mantenimento del Contesto: Le operazioni su più file funzionano senza problemi.
-
Velocità: L’inferenza in cloud è rapida.
Considerazioni Finali
Gemma 4 su Claude Code offre velocità e ottime prestazioni. Google ha rilasciato un modello di coding open-source davvero serio.
I benchmark si traducono in prestazioni reali. L’integrazione con Ollama Cloud rimuove la barriera hardware.
Se stavi aspettando un modello Google che funzionasse bene con Claude Code, eccolo qui.
Hai provato Gemma 4 su Claude Code? Fammi sapere la tua esperienza nei commenti qui sotto.
Rimaniamo in contatto!
Se sei nuovo ai miei contenuti, mi chiamo Joe Njenga
Unisciti a migliaia di altri ingegneri del software, esperti di AI e solopreneur che leggono i miei contenuti quotidianamente su Medium e su YouTube dove recensisco gli ultimi strumenti e tendenze dell’ingegneria AI. Se sei curioso di saperne di più sui miei progetti e vuoi ricevere guide e tutorial dettagliati, unisciti a migliaia di altri appassionati di AI nella mia newsletter settimanale AI Software engineer.
Se desideri contattarmi direttamente, puoi farlo qui:
AI Integration Software Engineer (Oltre 10 anni di esperienza)
Seguimi su Medium | Canale YouTube | X | LinkedIn
📝 Nota sulla traduzione
Questo articolo è stato tradotto automaticamente dall’inglese all’italiano utilizzando intelligenza artificiale.
L’articolo originale è disponibile su: https://medium.com/@joe.njenga/i-tried-gemma-4-on-claude-code-and-found-new-free-google-coding-beast-6d0995ba8645Tutti i diritti sui contenuti originali appartengono ai rispettivi proprietari. Questa traduzione è fornita a scopo informativo e non costituisce un’opera derivata con pretese di originalità.
Lascia un commento